BRM
UNIT – 3Data analysis and Interpretation Q1) Write a note on Editing.A1) Editing the raw data is the usual first step in the analysis. Editing detects mistakes and omissions, corrects them whenever possible and certifies the achievement of minimum data quality standards.The duty of the editor is to guarantee that information is;1. Precise, precise,2. In accordance with the intent of the question or with other information,3. entered uniformly,4. Complete, and5. Arranged for coding and tabulation simplification.Data editing can be achieved in two ways: field editing and in-house editing, also called central editing. Field editing is a field supervisor's preliminary editing of data on the same day as the interview. Its purpose is to identify technical omissions, check legibility, and clarify responses that are logically or conceptually inconsistent.When gaps from interviews are present, instead of guessing what the respondent "would probably have said," a call-back should be made.A second important task of the supervisor is to re-interview a few respondents, at least on some pre-selected questions, as a validity check. All the questionnaires undergo thorough editing in central or in-house editing. It is a rigorous job done by employees of the central office. Q2) What is Coding? A2) Coding is the process of assigning responses to numbers or other symbols in order to group the responses into a limited number of classes or categories. Coding allows the investigator to reduce several thousand responses to a few categories containing the critical data intended for the question asked.When the questionnaire itself is prepared, which we call pre-coding, or after the questionnaire has been administered, numerical coding can be incorporated. The questions, which we call post-coding, were answered.Pre-coding is necessarily limited primarily to questions whose categories of responses are known beforehand. These are mainly closed-ended questions (such as sex, religion) or questions that already have a number of answers and therefore do not need to be converted (such as age, number of children).For data entry, pre-coding is particularly useful because it makes the intermediate step of completing a coding sheet unnecessary. The data is directly accessible from the questionnaire.Depending on the method of data collection, a respondent interviewer field supervisor or researcher) can assign appropriate numerical responses to the instrument by checking or circling it in the correct coding locationThe main advantage of post-coding over pre-coding is that post-coding allows the coder to determine before starting coding which responses are provided by the respondent. This can contribute to great simplification. For each combination of responses given, post-coding also allows the researcher to code multiple responses to a single variable by writing a different code number.Coding, whether pre or post, is a two-part method that includes;1. For each possible answer category, the choice of a different number; and2. Choosing the appropriate column or column to contain the code numbers for those variables on the computer card.Some data detail is sacrificed by data coding, but it is necessary for efficient analysis. We could use the code "M" or "C." instead of asking the word Muslim or Christian for a question that asks for the identification of one's religion. This variable would normally be coded as 1 for Muslims and 2 for Christians. "The "QI" or "VI" type codes are called alphanumeric codes. The codes are numeric when numbers are used exclusively (e.g., 1, 2, etc.). The codebook is a type of booklet compiled by the survey staff that on a questionnaire tells the meaning of each code from each question.For instance, the codebook might disclose that the male is coded 1 and the female 2 for question number 10.The codebook is used as a guide by the investigator to make data entry less prone to error and more efficient. It is also the one thatDuring analysis, the definitive source for locating the positions of variables in the data file. If a questionnaire can be pre-coded completely, with an edge-code indicating the location of the variable in the data file, then it is not necessary to have a separate codebook and a blank questionnaire can be used as a codebook.However, there is not enough space on the questionnaire to identify all codes, especially for post-coding and for open-ended questions that receive many answers. Coding Non-responsesAs a result of failure to provide any answer to a question at all, non-response (or missing cases) occurs, and these are inevitable in any questionnaire.In order to avoid non-responses, care should be taken, but if these occur, the researcher must devise a system for coding them, preferably a standard system, so that the same code can be used for non-responses irrespective of the specific question.A numerical code should be assigned to a non-response.0 and 9 are the numbers most often used for non-response. The number is merely repeated for each column for variables that require more than one column (e.g., 99, 999). For non-response, any numerical code is satisfactory as long as it is not a number that might occur as a legitimate response.For instance, if you were to ask the respondent to list the number of children in their family, because you could not distinguish a non-response from a family of nine children, you should not use 9 for non-response.Code may also need to be assigned in addition to non-response items for "do not know" abbreviated "DK" responses and for "not applicable (NA)" responses, provided that the question does not apply to a particular respondent. Responses to 'Don't know' are often coded as 'O' or 'OO.' Q3) What are the types of Analysis of data?A3) Data analysis In order to discover useful information for business decision-making, data analysis is defined as a process of cleaning, transforming and modeling data. The purpose of Data Analysis is to extract useful data from the data and to make decisions based on the analysis of the data. A simple example of data analysis is to think about what happened last time or what will happen by choosing that specific decision whenever we make any decision in our day-to-day life. This is nothing but to analyze and make decisions based on our past or future. We collect memories of our past or dreams of our future for that. So that's nothing but an analysis of data. Data Analysis is now the same thing an analyst does for business purposes. Text AnalysisData Mining is also referred to as Text Analysis. It is one of the data analysis methods to discover a pattern using databases or data mining tools in large data sets. It has been used to transform raw data into business data. In the market that is used to make strategic business decisions, Business Intelligence instruments are present. Overall, it provides a way of extracting and examining information and deriving patterns, and finally interpreting the data. Statistical AnalysisStatistical analysis demonstrates "What happen?" in the form of dashboards using past data. Statistical analysis involves information gathering, analysis, interpretation, presentation, and modeling. It analyzes a set of information or a data sample. This type of analysis has two categories - descriptive analysis and inferential analysis. Descriptive AnalysisComplete data analysis or a sample of summarized numerical data analysis. For continuous data, it shows mean and deviation, while percentage and frequency for categorical data. Inferential AnalysisSample analysis from complete data. In this type of analysis, by selecting different samples, you can find different conclusions from the same data. Diagnostic Analysis"Why did it happen?" is shown by Diagnostic Analysis by finding the cause from the insight found in Statistical Analysis. This analysis is useful for the determination of data behavior patterns. If your business process has a new problem, then you can look into this analysis to find similar patterns of the problem. And it may have opportunities for the new issues to use similar prescriptions. Predictive AnalysisBy using previous data, Predictive Analysis shows "what is likely to happen" The simplest example of data analysis is that if I bought two clothes based on my savings last year, and if my salary doubles this year, then I can buy four clothes But, of course, this is not easy because you have to think about other circumstances, such as this year's chances of increasing clothing prices, or maybe you want to buy a new bike instead of clothes, or you need to buy a house! So here, based on existing or past data, this analysis makes predictions about future results. Forecasting is an estimate only. Its reliability is based on how much detailed data you have and how much you dig into it. Prescriptive AnalysisIn order to determine which action to take in a present problem or decision, Prescriptive Analysis combines the insight from all prior analysis. Prescriptive Analysis is used by most data-driven businesses because predictive and descriptive analytics are not sufficient to improve data performance. They analyze the data on the basis of current situations and problems and make decisions.A broad term that encompasses many different types of data analysis is data analytics. To obtain insight that can be used to enhance things, any type of data can be subjected to data analytics techniques. Manufacturing companies, for example, often record the runtime, downtime, and work queue for different machines and then analyze the data to plan the workloads better so that the machines operate closer to peak capacity.In production, data analytics can do much more than point out bottlenecks. To set reward schedules for players who keep the majority of players active in the game, gaming companies use data analytics. Many of the same data analytics are used by content companies to keep you clicking, watching, or re-organizing content to get another view or another click. Q4) Write the Significance of processing data.A4) Easy to make reports – It can be used directly, because the information has been processed. It is possible to organize these processed facts and figures in such a way that they can help operators to quickly conduct analysis. Predefined data helps experts to produce faster reports. Accuracy and speed - Digitization helps to quickly process data. It is possible to process thousands of files in a minute and save the necessary information from each file. The system will automatically check and process invalid or corrupted data in the process of processing business data. Such processes therefore help businesses ensure high accuracy in the management of information. Reduce costs – The cost of digital processing is much less than the management and maintenance of paper documents. It decreases the cost of purchasing stationery to store paper documents with information. Therefore, through improving their data management systems, businesses can save millions of dollars each year. Easy storage - helps to increase storage space, manage information and modify it. It minimizes clutter by eliminating unnecessary paperwork, and also improves search efficiency. A large number of businesses are in need of data processing outsourcing nowadays. For any company looking to improve its effectiveness, this data service is truly a premium service. Q5) Write a note: Multivariate analysis.A5) Suppose a project has been allocated to you to predict the company's sales. You can't just say that 'X' is the factor that will influence sales.We understand that there are various elements or variables that will affect sales. Only multivariate analysis can be found to analyze the variables that will majorly affect sales. And it will not be just one variable in most cases.As we know, sales will depend on the product category, production capacity, and geographical location, and marketing effort, market presence of the brand, analysis of competitors, product cost, and various other variables. Sales is only one example; in any section of most fields, this study can be implemented. In many industries, like healthcare, multivariate analysis is widely used. In the recent COVID-19 case, a team of data scientists predicted that by the end of July 2020, Delhi would have more than 5lakh COVID-19 patients. This analysis was based on various variables such as government decision-making, public conduct, population, occupation, public transport, health services, and community overall immunity.Multivariate analysis is also based on the Data Analysis study by Murtaza Haider of Ryerson University on the shore of the apartment, which leads to an increase in cost or a decrease in cost. As per that study, transport infrastructure was one of the major factors. People were thinking of buying a home at a location that offers better transport, and this is one of the least thought of variables at the beginning of the study, according to the analyzing team. But with analysis, this occurred in a few final variables that affected the result. Exploratory data analysis involves multivariate analysis. The deeper insight of several variables can be visualized based on MVA.To perform multivariate analysis, there are more than 20 different techniques and which method is best depends on the type of data and the problem you are trying to solve. Multivariate analysis (MVA) is a statistical method for data analysis involving more than one measurement or observation type. It may also mean solving issues where more than one dependent variable is analyzed with other variables simultaneously.Advantages and Disadvantages of Multivariate AnalysisThe main advantage of multivariate analysis is that the conclusion drawn is more precise because it considers more than one factor of independent variables affecting the variability of dependent variables. The conclusions are more realistic and closer to the situation in real life. DisadvantagesThe main disadvantage of MVA is that a satisfactory conclusion requires rather complex calculations. It is necessary to collect and tabulate many observations for many variables; it is a rather time-consuming method. Q6) How does the Chi-Square statistic work?A6) The Chi-Square statistics are most commonly used when using cross tabulation to evaluate Independence Tests (also known as a bivariate table). The distributions of two categorical variables are presented simultaneously by Cross tabulation, with the intersections of the categories of the variables appearing in the table cells. By comparing the observed pattern of responses in the cells to the pattern that would be expected if the variables were truly independent of each other, the Independence Test evaluates whether an association exists between the two variables. The researcher can evaluate whether the observed cell counts differ significantly from the expected cell counts by calculating the Chi-Square statistic and comparing it against a critical value from the Chi-Square distribution.The Chi-Square statistics calculation is fairly straightforward and intuitive:
Where fo = The frequency observed (the observed counts in the cells)And fe = The expected frequency if there was no relationship between the variablesThe Chi-Square statistic, as shown in the formula, is based on the difference between what is actually observed in the data and what would be expected if the variables were truly not related. Q7) How is the Chi-Square statistic run in SPSS and how is the output interpreted?A7) As an option when requesting a cross tabulation in SPSS, the Chi-Square statistic appears. Chi-Square Tests are labeled as the output; Pearson Chi-Square is the Chi-Square statistic used in the Independence Test. By comparing the actual value against a critical value found in a Chi-Square distribution (where degrees of freedom are calculated as # of rows-1 x # of columns-1), this statistic can be evaluated, but it is easier to simply examine the p-value provided by SPSS. The value is labeled as to conclude the hypothesis with 95 percent trust. Sig. Sec. (Which is the Chi-Square statistic's p-value) should be less than .055 (which is the alpha level associated with a 95 percent confidence level).Is less than .05 the p-value (labeled Asymp? Sig.)? If so, we can conclude that the variables are not independent of each other and that the categorical variables have a statistical relationship. There is an association in this instance between fundamentalism and views in public schools on teaching sex education. While 17.2% of fundamentalist people are opposed to teaching sex education, only 6.5% of liberals are opposed. The p-value indicates that these variables are not independent of each other and that the categorical variables have a statistically significant relationship. Q8) What are special concerns with regard to the Chi-Square statistic?A8) When using Chi-Square statistics to evaluate a cross tabulation, there are a number of significant considerations. It is extremely sensitive to sample size because of how the Chi-Square value is calculated; when the sample size is too large (~500), almost any small difference will appear statistically significant. It is also sensitive to the distribution within the cells, and if cells have fewer than 5 cases, SPSS gives a warning message. This can be addressed by always using categorical variables with a limited number of categories (for example, by combining categories to produce a smaller table if necessary). Q9) Write a note: Zandt-test (for large and small sample)A9) A z-test is a statistical test used when the variances are known and the sample size is large to determine whether two population meanings are different. The test statistics are assumed to have a normal distribution, and for an accurate z-test to be performed, nuisance parameters such as standard deviation should be known.A z-statistic, or z-score, is a number representing how many standard deviations a score derived from a z-test is above or below the mean population.A z-test is a statistical test to determine if when the variances are known and the sample size is large, two population meanings are different. It can be used for testing hypotheses in which a normal distribution follows the z-test. A z-statistic, or z-score, is a number that represents the z-test outcome. Z-tests are closely related to t-tests, but when an experiment has a small sample size, t-tests are best conducted. T-tests also assume that the standard deviation is unknown, whereas z-tests presume that it is known. How Z-Tests WorkA one-sample location test, a two-sample location test, a paired difference test, and a maximum likelihood estimate are examples of tests that can be conducted as z-tests. Z-tests are closely related to t-tests, but when an experiment has a small sample size, t-tests are best conducted. T-tests also presume that the standard deviation is unknown, whereas z-tests presume that it is known. The assumption of the sample variance equaling the population variance is made if the standard deviation of the population is unknown. Hypothesis TestThe z-test is also a test of hypotheses in which a normal distribution follows the z-statistic. For greater-than-30 samples, the z-test is best used because, under the central limit theorem, the samples are considered to be approximately normally distributed as the number of samples gets larger. The null and alternative hypotheses, alpha and z-score, should be stated when conducting a z-test. Next, it is necessary to calculate the test statistics and state the results and conclusions. One-Sample Z-Example TestAssume that an investor wishes to test whether a stock's average daily return is greater than 1%. It calculates a simple random sample of 50 returns and has an average of 2 percent. Assume that the standard return deviation is 2.5 percent. The null hypothesis, therefore, is when the average, or mean, equals 3%.The alternative hypothesis, on the other hand, is whether the average return is greater than 3% or less. Assume an alpha is selected with a two-tailed test of 0.05 percent. Therefore, in each tail, there is 0.025 percent of the samples, and the alpha has a critical value of 1.96 or -1.96. The null hypothesis is rejected if the value of z is greater than 1.96 or less than -1.96. The z-value is calculated by subtracting from the observed average of the samples the value of the average daily return selected for the test, or 1 percent in this case. Next, divide the resulting value by the standard deviation of the number of values observed, divided by the square root. It is therefore calculated that the test statistic is 2.83, or (0.02 - 0.01) / (0.025 / (50)^(1/2)). Since z is greater than 1.96, the investor rejects the null hypothesis and concludes that the average daily return is greater than 1 percent.
|
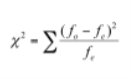





0 matching results found