Unit - 5
Reinforced and Deep Learning
Q1) What is reinforcement learning?
A1) Reinforcement Learning is a feedback-based Machine Learning technique in which an agent learns how to behave in a given environment by executing actions and seeing the outcomes of those actions. The agent receives positive feedback for each excellent action, and negative feedback or a penalty for each bad action.
Unlike supervised learning, the agent learns autonomously utilising feedback and no labelled data in Reinforcement Learning. Because there is no labelled data, the agent must rely only on its own experience to learn.
RL is used to tackle a certain sort of problem in which sequential decision-making is required and the aim is long-term, such as game-playing, robotics, and so on. The agent interacts with and explores the world on its own. In reinforcement learning, an agent's primary goal is to increase performance by obtaining the most positive rewards.
The agent learns through trial and error, and as a result of its experience, it improves its ability to complete the task. As a result, "reinforcement learning" can be defined as "a form of machine learning method in which an intelligent agent (computer programme) interacts with the environment and learns how to function within it." Reinforcement learning is demonstrated by the way a robotic dog learns to move his arms.
Reinforcement learning is a fundamental idea in artificial intelligence, and it is used by all AI agents. We don't need to programme the agent ahead of time because it learns from its own experiences without the need for human assistance.
Q2) Write the characteristics of reinforcement learning?
A2) You probably used the reinforcement learning method when you needed to figure out which situation requires an action or when you wanted to figure out which action delivers the most rewards over a lengthy period of time. Reinforcement learning is also important for obtaining the learning agent as well as the reward function, as well as estimating the best process or way to receive the highest reward.
Reinforcement learning demonstrates the following qualities as a result of the large number of specialties:
● There is no supervisor, simply a number or a signal of reward.
● Making decisions in a sequential order.
● In Reinforcement learning situations, time is key.
● Feedback is never instantaneous; it is always delayed.
● The data that the agent receives is determined by its actions.
Q3) What are the approaches to implement reinforcement learning?
A3) A Reinforcement Learning algorithm can be implemented in three ways.
Value-Based:
You should strive to optimise a value function V in a value-based Reinforcement Learning approach (s). In this strategy, the agent anticipates a long-term return of the current policy states.
Policy-based:
In a policy-based RL method, you strive to come up with a policy that allows you to get the most reward in the future by doing actions in each state.
There are two sorts of policy-based methods:
● Deterministic - The policy produces the same action for each state.
● Stochastic - Every action has a probability, which can be calculated using the equation below.
Stochastic Policy
n{a\s) = P\A, = a\S, =S]
Model-Based:
You must develop a virtual model for each environment in this Reinforcement Learning approach. The agent learns how to perform in that particular setting.
Q4) Write the difference between positive and negative reinforced learning?
A4) Difference between positive and negative reinforced learning
BASIS FOR COMPARISON | POSITIVE REINFORCEMENT | NEGATIVE REINFORCEMENT |
Meaning | Positive Reinforcement refers to the technique of introducing a stimulus in order to increase the likelihood of a pattern or behaviour repeating itself. | Negative reinforcement is when a negative stimulus is removed in order to encourage positive behaviour. |
Stimuli | Added | Removed |
Consequences | Stimuli have a positive impact. | Stimuli have unfavourable outcomes. |
Reinforcer acts as | Reward | Penalty |
Results in | Strengthening and maintaining responses | Avoiding and escaping responses. |
Q5) Write short notes on positive reinforced learning?
A5) Positive reinforcement learning
Positive reinforcement is defined as the process of encouraging a desired behaviour by providing a reward as a stimulus when that behaviour is demonstrated. In other words, if an activity produces a good response or reward, the response is likely to be reinforced.
The goal is to enhance the likelihood of the pattern or behaviour occurring. Positive reinforcers can be a desirable outcome that satisfies requirements like as food, water, money, status, medals, and so on, or they might be a barrier that is removed in the need satisfaction process.
Example
● A commercial for a health drink that shows a rise in height as a result of drinking it is an example of Positive Reinforcement, in which the gain in height is the reinforcer to buy the health drink.
● The Internal Revenue Service is giving gifts to genuine assessees.
● Employees are granted promotions as a kind of reinforcement if they meet their sales targets.
One thing to keep in mind is that a good reinforcer might mean different things to different people. For example, a manager's appreciation can be a powerful reinforcer for some employees, but not for all, and a promotion or increment can be a powerful reinforcer for others.
Q6) Write about negative reinforced learning?
A6) Negative reinforcement learning
When a reinforcer, i.e. stimulus, is eliminated as a result of a specific behaviour, this is referred to as 'negative reinforcement.' As a result of removing the negative effect, the frequency of occurrence of the behaviour will grow in the future. In a nutshell, negative reinforcement refers to the use of an aversive stimuli. Because the reinforcer is negative and the person tries to avoid or escape from it, it is also known as escape or avoidance learning.
It differs from punishment in that punishment reduces the likelihood of the behaviour occurring, whereas negative reinforcement enhances the likelihood of the behaviour occurring.
Example
● During the rainy season, a person learns to wear a raincoat to avoid getting wet.
● People wear helmets to avoid being hurt in a car accident or being ticketed by the cops.
Q7) Explain Markov Decision Process?
A7) To formalise reinforcement learning problems, the Markov Decision Process (MDP) is used. If the environment is totally observable, a Markov Process can be used to model its dynamics. The agent in MDP constantly interacts with the environment and performs actions; the environment responds to each action and develops a new state.
To obtain a solution, the following parameters are used:
● Set of actions- A
● Set of states -S
● Reward- R
● Policy- n
● Value- V
The mathematical method for mapping a reinforcement solution Learning is renamed a Markov Decision Process or MDP for short (MDP).
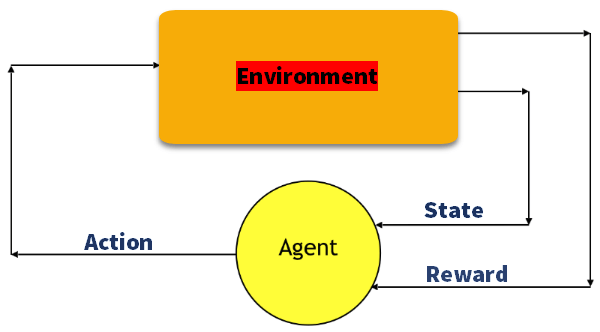
Fig 1: Markov decision process
Markov Property:
"If the agent is in the current state S1, performs action a1, and then moves to the state s2, the state transition from s1 to s2 is only dependent on the current state and future action, and states are independent of past actions, rewards, or states," it says.
Or, to put it another way, the present state transition is independent of any previous action or state, according to the Markov Property. As a result, MDP is a Markov property-satisfying RL issue. In a game like Chess, the players are just concerned with the current state and do not need to recall previous actions or states.
Finite MDP:
There are finite states, finite rewards, and finite actions in a finite MDP. Only the finite MDP is considered in RL.
Markov Process:
The Markov Process is a memoryless process that employs the Markov Property and has a sequence of random states S1, S2,...., St. The Markov process, often known as the Markov chain, is a tuple (S, P) based on the state S and the transition function P. The system's dynamics can be defined by these two components (S and P).
State
A state is a collection of tokens that represent every possible state for the agent.
Model
A Model (also known as a Transition Model) describes how an action affects a state. T(S, a, S') specifies a transition T that occurs when we are in state S and do action 'a', resulting in state S' (S and S' may be the same). We also construct a probability P(S'|S,a) for stochastic actions (noisy, non-deterministic), which is the chance of reaching a state S' if action 'a' is conducted in state S. Note that the Markov property asserts that the results of an action made in a state are solely determined by that state and not by previous history.
Action
A course of action A is a collection of all actions that can be taken. The collection of actions that can be executed while in state S is defined by A(s).
Reward
A Reward is a reward function with a real value. The reward for simply being in the state S is R(s). The reward for being in state S and doing action 'a' is R(S,a). The reward for being in state S, taking action 'a', and ending up in state S' is R(S,a,S').
Q8) Write the features of reinforcement learning?
A8) Features of Reinforcement learning
● In real life, the agent is not given any instructions regarding the surroundings or the tasks that must be taken.
● It is based on the hit-or-miss method.
● The agent performs the next action and changes states in response to the previous activity's feedback.
● A delayed incentive could be given to the agent.
● Because the environment is stochastic, the agent must explore it in order to maximize positive rewards.
Q9) Describe Q-Learning?
A9) It's a value-based model-free method of informing an agent about the action he or she should take. It is based on the concept of updating Q values, which demonstrates the value of performing action A in state S. The essential feature of the Q-learning algorithm is the value updating rule.
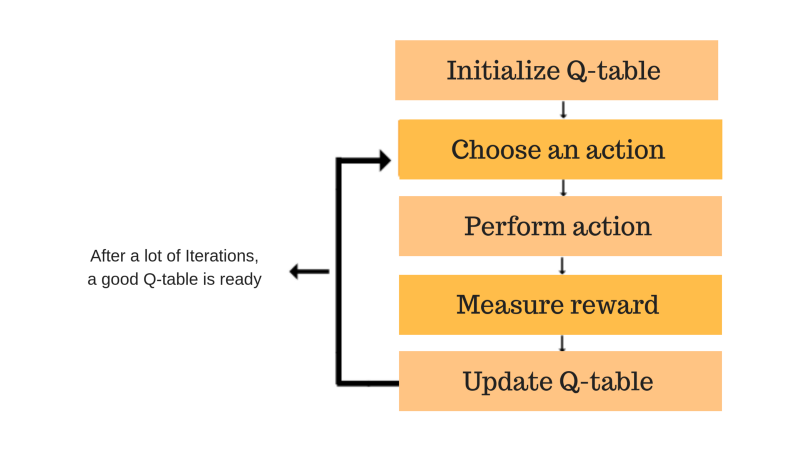
Fig 2: Q – learning
Given a current state, Q-Learning is a Reinforcement learning policy that will determine the next best action. It selects this action at random with the goal of maximising the reward.
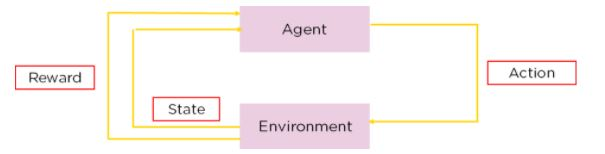
Fig 3: Components of Q-Learning
Given the present state of the agent, Q-learning is a model-free, off-policy reinforcement learning that will determine the best course of action. The agent will pick what action to take next based on where it is in the environment.
The model's goal is to determine the optimum course of action given the current situation. To accomplish this, it may devise its own set of rules or act outside of the policy that has been established for it to obey. This means there isn't a real need for a policy, which is why it's called off-policy.
Model-free indicates that the agent moves forward based on estimates of the environment's expected response. It does not learn through a reward system, but rather by trial and error.
A recommendation system for advertisements is an example of Q-learning. Ads you see in a traditional ad suggestion system are based on previous purchases or websites you've visited. If you've purchased a television, you'll be given recommendations for televisions from various companies.
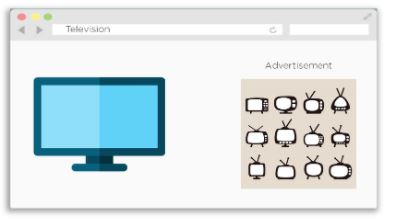
Fig 4: Ad Recommendation System
Important Terms in Q-Learning
State - The state, S, represents an agent's current position in a given environment.
Action - The action, A, is the action that the agent takes when it is in a certain state.
Reward - The agent will receive a good or negative reward for each activity.
Episodes - When an agent becomes stuck in a terminating condition and is unable to do any further activity.
Q-Values - are used to determine the quality of an Action, A, taken at a specific state, S. Q: (A, S).
Temporal Difference - A formula for calculating the Q-Value by combining the values of the current and earlier states and actions.
Q10) Define deep learning?
A10) Deep learning is based on the branch of machine learning, which is a subset of artificial intelligence. Since neural networks imitate the human brain and so deep learning will do. In deep learning, nothing is programmed explicitly. Basically, it is a machine learning class that makes use of numerous nonlinear processing units so as to perform feature extraction as well as transformation. The output from each preceding layer is taken as input by each one of the successive layers.
Deep learning models are capable enough to focus on the accurate features themselves by requiring a little guidance from the programmer and are very helpful in solving out the problem of dimensionality. Deep learning algorithms are used, especially when we have a huge no of inputs and outputs.
Since deep learning has been evolved by the machine learning, which itself is a subset of artificial intelligence and as the idea behind the artificial intelligence is to mimic the human behavior, so same is "the idea of deep learning to build such algorithm that can mimic the brain".
Deep learning is implemented with the help of Neural Networks, and the idea behind the motivation of Neural network is the biological neurons, which is nothing but a brain cell.
Deep learning is a collection of statistical techniques of machine learning for learning feature hierarchies that are actually based on artificial neural networks.
So basically, deep learning is implemented by the help of deep networks, which are nothing but neural networks with multiple hidden layers.
Q11) Write the characteristics of deep learning?
A11) Deep Learning has the following characteristics:
1. Supervised, Semi-Supervised or Unsupervised
Supervised learning occurs when category labels are present when the data is being trained. Linear regression is an example of an algorithm. Supervised Learning is used in decision trees and logistic regression. Unsupervised learning occurs when category labels are unknown when training data. Unsupervised Learning is used in algorithms such as Cluster Analysis, K means clustering, and Anomaly detection. Semi-Supervised learning occurs when the data set contains both labelled and unlabeled data. Semi-Supervised learning is used in graph-based models, generative models, cluster assumptions, and continuity assumptions.
2. Huge Amount of Resources
Processing huge workloads necessitates sophisticated Graphical Processing Units. Big data, which can be structured or unstructured, requires the processing of a large volume of data. Depending on the amount of data sent in, more time may be necessary to process the data.
3. Large Amount of Layers in Model
A large number of layers, such as input, activation, and output, will be necessary; sometimes the output of one layer can be fed to another layer by making a few minor discoveries, which are then summed together in the softmax layer to determine a broader categorization for the final output.
4. Optimizing Hyper-parameters
Because it forms a relationship between layer predictions and final output prediction, hyper factors like the number of epochs, Batch size, No of layers, and Learning rate must be fine-tuned for effective Model accuracy. Hyper-parameters can effectively handle overfitting and under-fitting.
5. Cost Function
It expresses how well the model performs in terms of accuracy and prediction. The purpose of each iteration in a Deep Learning Model is to reduce the cost in comparison to previous iterations. According to the techniques utilised, mean absolute error, mean squared error, hinge loss, and cross entropy are various forms.
Q12) What is an artificial neural network?
A12) Biological neural networks establish the structure of the human brain, and the phrase "Artificial Neural Network" is taken from them. Artificial neural networks, like the human brain, have neurons that are coupled to one another in various layers of the networks. Nodes are the name for these neurons.
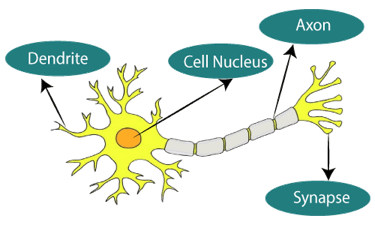
Fig 5: Neurons
The diagram seen here is a typical Biological Neural Network diagram.
The standard Artificial Neural Network resembles the illustration below.
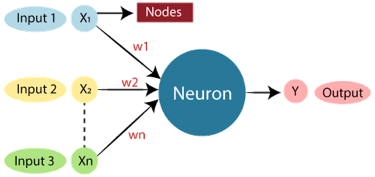
Fig 6: ANN
In Artificial Neural Networks, dendrites from biological neural networks represent inputs, cell nuclei represent nodes, synapse represent weights, and axon represent output.
In the science of artificial intelligence, an Artificial Neural Network seeks to duplicate the network of neurons that make up a human brain so that computers can understand things and make judgments in a human-like fashion. Computers are programmed to act like interconnected brain cells in order to create an artificial neural network.
The human brain contains approximately 1000 billion neurons. Each neuron has a number of association points ranging from 1,000 to 100,000. Data is stored in the human brain in such a way that it may be spread, and we can pull multiple pieces of this data from our memory at the same time if needed. The human brain, we may say, is made up of incredible parallel processors.
Consider the example of a digital logic gate that receives an input and produces an output to better understand the artificial neural network. The "OR" gate accepts two inputs. If one or both inputs are "On," the output will be "On." If both inputs are "Off," the output will be "Off." In this case, the output is determined by the input. Our brains don't work in the same way. Because our brain's neurons are "learning," the output to input connections is constantly changing.
Q13) What is the architecture of ANN?
A13) To comprehend the concept of artificial neural network architecture, we must first comprehend what a neural network is made up of. To describe a neural network that is made up of a large number of artificial neurons called units that are stacked in layers. Let's take a look at the various layers that may be found in an artificial neural network.
The Artificial Neural Network is made up of three layers:
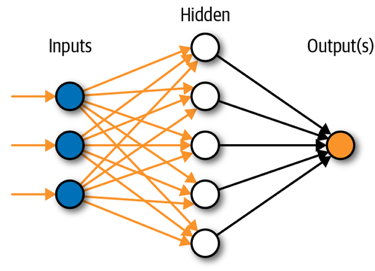
Fig 7: Architecture of ANN
- Input layer
It accepts inputs in a variety of formats specified by the programmer, as the name implies.
2. Hidden layer
Between the input and output layers is a concealed layer. It does all the math to uncover hidden features and patterns.
3. Output layer
The input goes through a series of transformations using the hidden layer, which finally results in output that is conveyed using this layer.
The artificial neural network takes input and computes the weighted sum of the inputs and includes a bias. This computation is represented in the form of a transfer function.
Q14) Write the advantages and disadvantages of ANN?
A14) Advantages
● Parallel processing capability:
Artificial neural networks have a numerical value that allows them to accomplish multiple tasks at once.
● Storing data on the entire network:
Traditional programming data is saved across the entire network, not in a database. The network continues to function despite the loss of a few pieces of data in one location.
● Capability to work with incomplete knowledge:
Even with insufficient data, after ANN training, the information may produce output. The relevance of missing data is what causes the performance loss in this case.
● Having a memory distribution:
It is critical to determine the examples and to stimulate the network according to the intended output by displaying these examples to the network if the ANN is to be able to adapt.
● Having fault tolerance:
The loss of one or more ANN cells does not prevent the network from producing output, and this feature makes the network fault-tolerant.
Disadvantages
● Assurance of proper network structure:
The structure of artificial neural networks can be determined in a variety of ways. Experience, trial, and error are used to create the ideal network structure.
● Unrecognized behavior of the network:
It is ANN's most important problem. When ANN creates a testing solution, it does not explain why or how it was created. It erodes the network's trustworthiness.
● Hardware dependence:
Artificial neural networks, due to their structure, require computers with parallel processing power. As a result, the equipment's manifestation is contingent.
● Difficulty of showing the issue to the network:
ANNs are capable of working with numerical data. Before introducing problems to ANN, they must be transformed into numerical values. The presentation mechanism that must be resolved here will have a direct impact on the network's performance. It is dependent on the user's capabilities.
● The duration of the network is unknown:
The network is reduced to a specified error value, which does not provide us the best outcomes.
Q15) Define CNN?
A15) Convolutional neural networks are composed of multiple layers of artificial neurons. Artificial neurons, a rough imitation of their biological counterparts, are mathematical functions that calculate the weighted sum of multiple inputs and outputs an activation value.
Convolutional neural networks are made up of two basic components: convolutional layers and pooling layers.
There are nearly limitless ways to assemble these layers for a particular computer vision issue, despite their simplicity.
Convolutional and pooling layers, for example, are rather simple to comprehend in a convolutional neural network.
The most difficult aspect of employing convolutional neural networks in reality is figuring out how to create model topologies that make the most of these basic components.
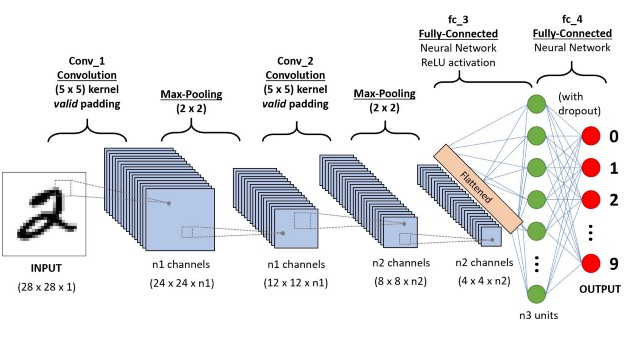
Fig 8: Convolutional Neural Networks
The behaviour of each neuron is defined by its weights. When fed with the pixel values, the artificial neurons of a CNN pick out various visual features.
When you input an image into a ConvNet, each of its layers generates several activation maps. Activation maps highlight the relevant features of the image. Each of the neurons takes a patch of pixels as input, multiplies their colour values by its weights, sums them up, and runs them through the activation function.
The first (or bottom) layer of the CNN usually detects basic features such as horizontal, vertical, and diagonal edges. The output of the first layer is fed as input of the next layer, which extracts more complex features, such as corners and combinations of edges. As you move deeper into the convolutional neural network, the layers start detecting higher-level features such as objects, faces, and more.




