Unit - 1
Introduction to AI & ML
Q1) Write the history of AI?
A1) Artificial Intelligence is not a new word and not a new technology for researchers. This technology is much older than you would imagine. Even there are the myths of Mechanical men in Ancient Greek and Egyptian Myths. Following are some milestones in the history of AI which defines the journey from the AI generation to till date development.
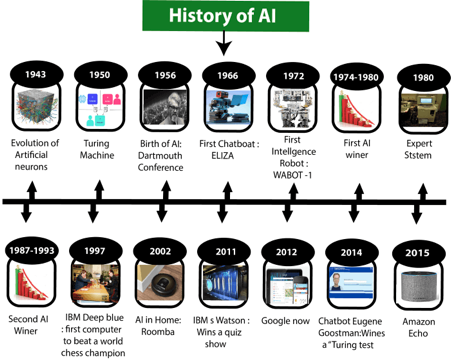
Fig: History of AI
Maturation of Artificial Intelligence (1943-1952)
● Year 1943: The first work which is now recognized as AI was done by Warren McCulloch and Walter pits in 1943. They proposed a model of artificial neurons.
● Year 1949: Donald Hebb demonstrated an updating rule for modifying the connection strength between neurons. His rule is now called Hebbian learning.
● Year 1950: The Alan Turing who was an English mathematician and pioneered Machine learning in 1950. Alan Turing publishes "Computing Machinery and Intelligence" in which he proposed a test. The test can check the machine's ability to exhibit intelligent behavior equivalent to human intelligence, called a Turing test.
The birth of Artificial Intelligence (1952-1956)
● Year 1955: An Allen Newell and Herbert A. Simon created the "first artificial intelligence program "Which was named as "Logic Theorist". This program had proved 38 of 52 Mathematics theorems, and find new and more elegant proofs for some theorems.
● Year 1956: The word "Artificial Intelligence" first adopted by American Computer scientist John McCarthy at the Dartmouth Conference. For the first time, AI coined as an academic field.
At that time high-level computer languages such as FORTRAN, LISP, or COBOL were invented. And the enthusiasm for AI was very high at that time.
The golden years-Early enthusiasm (1956-1974)
● Year 1966: The researchers emphasized developing algorithms which can solve mathematical problems. Joseph Weizenbaum created the first chatbot in 1966, which was named as ELIZA.
● Year 1972: The first intelligent humanoid robot was built in Japan which was named as WABOT-1.
The first AI winter (1974-1980)
● The duration between years 1974 to 1980 was the first AI winter duration. AI winter refers to the time period where computer scientist dealt with a severe shortage of funding from government for AI researches.
● During AI winters, an interest of publicity on artificial intelligence was decreased.
A boom of AI (1980-1987)
● Year 1980: After AI winter duration, AI came back with "Expert System". Expert systems were programmed that emulate the decision-making ability of a human expert.
● In the Year 1980, the first national conference of the American Association of Artificial Intelligence was held at Stanford University.
The second AI winter (1987-1993)
● The duration between the years 1987 to 1993 was the second AI Winter duration.
● Again, Investors and government stopped in funding for AI research as due to high cost but not efficient result. The expert system such as XCON was very cost effective.
The emergence of intelligent agents (1993-2011)
● Year 1997: In the year 1997, IBM Deep Blue beats world chess champion, Gary Kasparov, and became the first computer to beat a world chess champion.
● Year 2002: for the first time, AI entered the home in the form of Roomba, a vacuum cleaner.
● Year 2006: AI came in the Business world till the year 2006. Companies like Facebook, Twitter, and Netflix also started using AI.
Deep learning, big data and artificial general intelligence (2011-present)
● Year 2011: In the year 2011, IBM's Watson won jeopardy, a quiz show, where it had to solve the complex questions as well as riddles. Watson had proved that it could understand natural language and can solve tricky questions quickly.
● Year 2012: Google has launched an Android app feature "Google now", which was able to provide information to the user as a prediction.
● Year 2014: In the year 2014, Chatbot "Eugene Goostman" won a competition in the infamous "Turing test."
● Year 2018: The "Project Debater" from IBM debated on complex topics with two master debaters and also performed extremely well.
● Google has demonstrated an AI program "Duplex" which was a virtual assistant and which had taken hairdresser appointment on call, and lady on other side didn't notice that she was talking with the machine.
Now AI has developed to a remarkable level. The concept of Deep learning, big data, and data science are now trending like a boom. Nowadays companies like Google, Facebook, IBM, and Amazon are working with AI and creating amazing devices. The future of Artificial Intelligence is inspiring and will come with high intelligence.
Q2) Compare AI with Data science?
A2) key differences between the two most sought-after technologies:
Comparison Factor | Data Science | Artificial Intelligence |
Meaning | The goal of data science is to curate large amounts of data for analytics and visualisation. | Artificial Intelligence aids in the implementation of data and machine knowledge. |
Skills | For development and design, you'll need to employ statistical methods. | For development and design, you must employ algorithms. |
Technique | The Data Analytics approach is used in Data Science. | Deep Learning and Machine Learning approaches are used in AI. |
Observation | To make well-informed decisions, it looks for patterns in data. | It imbues robots with intelligence through the use of data, causing them to respond in the same way humans do. |
Solving Issues | It solves specific problems by utilising portions of a loop or programme. | AI, on the other hand, represents the planning and perception loop. |
Processing | It uses a medium level of data processing for data manipulation | It manipulates data using high-level scientific data processing. |
Graphic | It allows you to see data in a variety of ways. | It facilitates the adoption of a network node representation algorithm. |
Tools Involved | SAS, SPSS, Keras, R, Python, and other tools are used in data science. | Shogun, Mahout, Caffe, PyTorch, TensorFlow, Scikit-Learn, and other AI tools are used. |
Applications | Data Science applications are widely employed in Internet search engines such as Yahoo, Bing, and Google. | Transportation, healthcare, manufacturing, robotics, and other industries all use AI applications. |
Q3) What are the needs of AI in mechanical engineering?
A3) Some mechanical engineering domains are about to undergo a paradigm shift as a result of AI.
AI Helping in Complex CAD
In most cases, AI utilised in Computer-Aided Design (CAD) is based on knowledge-based systems. In CAD, design artefacts, rules, and problems are saved for subsequent use by CAD designers. Model-Based Reasoning is used to bring AI and CAD together (MBR). Knowledge-based systems are used in a lot of new software releases. Generative Design is a key field in which AI can be used. A tool for generative design takes design requirements as input and outputs viable designs. In its 2018 version, SolidWorks includes a topology optimization function that uses a generative design-based method.
Dreamcatcher is an Autodesk project that includes the feature of generative design. Instead of using the hit-and-trail method, engineers can use this tool to select a design provided by software after observing appropriate trade-offs for any features.
Artificial Neural Networks in CFD
Computational Fluid Dynamics has piqued scientists', engineers', and mathematicians' interest. Because of the turbulence and chaos associated with fluid physics, Direct Numerical Simulation has proven to be extremely challenging to solve (DNS). There are some models that mimic flow behaviour, such as Reynolds-Averaged Navier-Stokes equation (RANS) and Large Eddy Simulation (LES), and AI has found its way among them. Artificial Neural Networks (ANN) are gaining popularity in academia due to their ability to provide flow approximations with less computing power, reduced time, and reduced dimensionality of problems. They also accord well with CFD models that have been used for a long time. The task at hand is to teach ANN with a large number of sample simulations. Furthermore, neural networks do not provide insight into flow mechanisms.
IoT and Data Analysis
The fourth industrial revolution will connect all machinery in a manufacturing facility and consumer products, allowing engineers to analyse, optimise, and ensure product quality. Engineers who can read between the lines of sensor data will be required to manage such technical data. Mechanical engineers with AI skills would be needed to work on software that can manage data from sensors in power plant, manufacturing, or consumer product components. The application of data science in power plant optimization is one example. Data from Supervisory Control And Data Acquisition (SCADA) systems can be used to predict failures and save money and lives.
Sparkcognition, a firm based in the United States, provides solutions to power companies that detect anomalies in plant data and forecast any failure in advance, preventing downtime and revenue loss. Self-driving automobiles and industrial robotics are both benefiting from AI.
Q4) Introduce machine learning?
A4) Arthur Samuel, an American pioneer in the fields of computer games and artificial intelligence, invented the phrase Machine Learning in 1959, stating that "it offers computers the ability to learn without being expressly taught."
"A computer programme is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, increases with experience E," Tom Mitchell wrote in 1997.
At a high-level, machine learning is simply the study of teaching a computer programme or algorithm how to gradually improve upon a set task that it is given. On the research-side of things, machine learning can be seen through the prism of theoretical and mathematical simulation of how this method works. However, more technically it is the study of how to construct applications that exhibit this iterative progress.
Machine Learning is an Application of Artificial Intelligence (AI) that gives machines the opportunity to learn from their experiences and develop themselves without doing any coding.
Machine Learning is a branch of Artificial Intelligence. Machine Learning is the study of making machines more human-like in their actions and decisions by allowing them the ability to learn and create their own programmes. This is achieved with minimal human interference, i.e., no explicit programming. The learning process is automated and enhanced based on the experiences of the machines in the process.
In the real world, we are surrounded by individuals who can learn anything from their experiences thanks to their ability to learn, and we have computers or machines that follow our commands. But, like a human, can a machine learn from past experiences or data? So here's where Machine Learning comes in.
Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms that allow a computer to learn on its own from data and previous experiences. Arthur Samuel was the first to coin the term "machine learning" in 1959. In a nutshell, we can characterise it as follows:
“Machine learning enables a machine to automatically learn from data, improve performance from experiences, and predict things without being explicitly programmed.”
Machine learning algorithms create a mathematical model with the help of sample historical data, referred to as training data, that aids in making predictions or judgments without being explicitly programmed. In order to create predictive models, machine learning combines computer science and statistics. Machine learning is the process of creating or employing algorithms that learn from past data. The more information we supply, the better our performance will be.
If a system can enhance its performance by gaining new data, it has the potential to learn.
Q5) Write the features of ML?
A5) Features of ML
● Data is used by machine learning to find distinct patterns in a dataset.
● It can learn from previous data and improve on its own.
● It is a technology that is based on data.
● Data mining and machine learning are very similar in that they both deal with large amounts of data.
Q6) What is reasoning?
A6) The mental process of deducing logical conclusions and forming predictions from accessible knowledge, facts, and beliefs is known as reasoning. "Reasoning is a way to deduce facts from existing data," we can state. It is a general method of reasoning to arrive at valid conclusions.
In artificial intelligence, reasoning is required so that the machine can think rationally and perform as well as a human brain.
Types of reasoning
Reasoning can be classified into the following categories in artificial intelligence:
● Deductive reasoning
● Inductive reasoning
● Abductive reasoning
● Common Sense Reasoning
● Monotonic Reasoning
● Non-monotonic Reasoning
Deductive reasoning
Deductive reasoning is the process of deducing new information from previously known information that is logically linked. It is a type of legitimate reasoning in which the conclusion of an argument must be true if the premises are true.
In AI, deductive reasoning is a sort of propositional logic that necessitates a number of rules and facts. It's also known as top-down reasoning, and it's the polar opposite of inductive reasoning.
The truth of the premises ensures the truth of the conclusion in deductive reasoning.
Inductive reasoning
Inductive reasoning is a type of reasoning that uses the process of generalisation to arrive at a conclusion with a limited collection of information. It begins with a set of precise facts or data and ends with a broad assertion or conclusion.
Inductive reasoning, often known as cause-effect reasoning or bottom-up reasoning, is a kind of propositional logic.
In inductive reasoning, we use historical evidence or a set of premises to come up with a general rule, the premises of which support the conclusion.
The truth of premises does not ensure the truth of the conclusion in inductive reasoning because premises provide likely grounds for the conclusion.
Abductive reasoning
Abductive reasoning is a type of logical reasoning that begins with a single or several observations and then searches for the most plausible explanation or conclusion for the observation.
The premises do not guarantee the conclusion in abductive reasoning, which is an extension of deductive reasoning.
Common Sense Reasoning
Common sense thinking is a type of informal reasoning that can be learned through personal experience.
Common Sense thinking mimics the human ability to make educated guesses about occurrences that occur on a daily basis.
It runs on heuristic knowledge and heuristic rules and depends on good judgement rather than exact reasoning.
Monotonic Reasoning
When using monotonic reasoning, once a conclusion is reached, it will remain the same even if new information is added to the existing knowledge base. Adding knowledge to a monotonic reasoning system does not reduce the number of prepositions that can be deduced.
We can get a correct conclusion from the available data alone to address monotone problems, and it will not be influenced by fresh facts.
Monotonic reasoning is ineffective for real-time systems because facts change in real time, making monotonic reasoning ineffective.
In traditional reasoning systems, monotonic reasoning is applied, and a logic-based system is monotonic.
Non-monotonic Reasoning
Some findings in non-monotonic reasoning may be refuted if we add more information to our knowledge base.
If certain conclusions can be disproved by adding new knowledge to our knowledge base, logic is said to be non-monotonic.
Non-monotonic reasoning deals with models that are partial or uncertain.
Q7) Define Problem solving?
A7) Problem solving
● The AI reflex agent converts states into actions. When these agents fail to work in an environment where the state of mapping is too vast for the agent to handle, the stated problem dissolves and is delivered to a problem-solving domain, which divides the large stored problem into smaller storage areas and resolves them one at a time. The desired objectives will be the final integrated action.
● Different sorts of issue-solving agents are defined and used at an atomic level without any internal state observable with a problem-solving algorithm based on the problem and their working domain. By describing problems and many solutions, the problem-solving agent executes precisely. So we may say that issue solving is a subset of artificial intelligence that includes a variety of problem-solving approaches such as tree, B-tree, and heuristic algorithms.
● Because they immediately transfer states to actions, reflex agents are characterized as the simplest agents. Unfortunately, these agents are unable to function in situations where the mapping is too huge to store and learn. On the other hand, a goal-based agent considers future behaviours as well as the desired outcomes.
● The problem-solving agent is a sort of goal-based agent that uses atomic representation and has no internal states observable to the problem-solving algorithms.
● AI issue-solving steps: The nature of humans and their actions is closely related to the challenge of AI. As a result, we require a set of defined steps to solve an issue, which makes human labour simple.
These are the steps that must be completed in order to solve a problem:
● Goal Formulation: This is the first and most basic stage in fixing an issue. It organises discrete steps to establish a target/goals that necessitate some action in order to be achieved. AI agents are currently used to formulate the goal.
● Formulation of the Problem: It is one of the most important elements in the
● Problem-solving: process since it determines what action should be performed to attain the stated goal. This essential aspect of AI is reliant on a software agent, which consists of the components listed below to formulate the linked problem.
● Components needed to formulate the problem:
● Initial state: This state necessitates a beginning state for the task, which directs the AI agent toward a predetermined goal. In this condition, new methods also initialise a specific class to solve the problem domain.
● Action: In this stage of issue formulation, all feasible actions are performed using a function with a specific class taken from the initial state.
● Transition: In this step of issue formulation, the actual action taken by the previous action stage is combined with the final stage to be passed on to the next stage.
● Goal test: This stage determines if the integrated transition model achieved the specified goal or not; if it did, stop the activity and move on to the next stage to calculate the cost of achieving the goal.
● Path costing: is a component of problem-solving that assigns a numerical value to the expense of achieving the goal. It necessitates the purchase of all necessary hardware, software, and human labour.
Q8) Explain Knowledge representations?
A8) Humans are best at understanding, reasoning, and interpreting knowledge. Humans know things, which is that of the knowledge and as per that of their knowledge they perform several of the actions in that of the real world. But how machines do all of these things come under the knowledge representation and the reasoning. Hence we can describe that of the Knowledge representation as follows:
● Knowledge representation and reasoning (KR, KRR) is the part of Artificial intelligence which is concerned with AI agents thinking and how thinking contributes to intelligent behaviour of agents.
● It is responsible for representing information about the real world so that a computer can understand and then can utilize that knowledge to solve complex real world problems for instance diagnosis a medical condition or communicating with humans in natural language.
● It is also a way which describes that how we can represent that of the knowledge in that of the artificial intelligence. Knowledge representation is not just that of the storing data into some of the database, but it also enables of an intelligent machine to learn from that of the knowledge and experiences so that of the it can behave intelligently like that of a human.
What to Represent:
Following are the kind of knowledge which needs to be represented in that of the AI systems:
● Object: All the facts about that of the objects in our world domain. Example Guitars contains strings, trumpets are brass instruments.
● Events: Events are the actions which occur in our world.
● Performance: It describes that of the behaviour which involves the knowledge about how to do things.
● Meta-knowledge: It is knowledge about what we know.
● Facts: Facts are the truths about the real world and what we represent.
● Knowledge-Base: The central component of the knowledge-based agents is the knowledge base. It is represented as KB. The Knowledgebase is a group of the Sentences (Here, sentences are used as a technical term and not identical with the English language).
Knowledge: Knowledge is the awareness or familiarity gained by that of the experiences of facts, data, and situations. Following are the types of knowledge in artificial intelligence:
Q9) What are the types of knowledge?
A9) Following are the various types of knowledge:
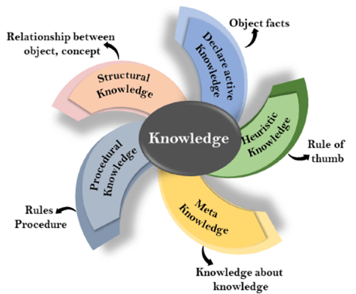
Fig 2: Types of knowledge
1. Declarative Knowledge:
● Declarative knowledge is to know about something.
● It includes the concepts, the facts, and the objects.
● It is also called descriptive knowledge and expressed in declarative sentences.
● It is simpler than procedural language.
2. Procedural Knowledge
● It is also known as imperative knowledge.
● Procedural knowledge is a type of knowledge which is responsible for knowing how to do something.
● It can be directly applied to any task.
● It includes rules, strategies, procedures, agendas, etc.
● Procedural knowledge depends on the task on which it can be applied.
3. Meta-knowledge:
● Knowledge about the other types of that of the knowledge is known as Meta-knowledge.
4. Heuristic knowledge:
● Heuristic knowledge is representing knowledge of some experts in a filed or subject.
● Heuristic knowledge is the rules of the thumb based on the previous experiences, awareness of the approaches, and which are good to that of the work but not guaranteed.
5. Structural knowledge:
● Structural knowledge is basic knowledge of problem-solving.
● It describes relationships between various concepts such as kind of, part of, and grouping of something.
● It describes the relationship that exists between concepts or objects.
The relation between knowledge and intelligence they are as follows:
Knowledge of real-worlds plays a very important role in intelligence and the same for creating artificial intelligence. Knowledge plays an important role in demonstrating intelligent behaviour in the AI agents. An agent is only able to accurately act on some of the input when he has some of the knowledge or the experience about that of the input.
Let's suppose if you met some of the people who are speaking in a language which you don't know, then how you will be able to act on that. The same thing applies to that of the intelligent behaviour of the agents.
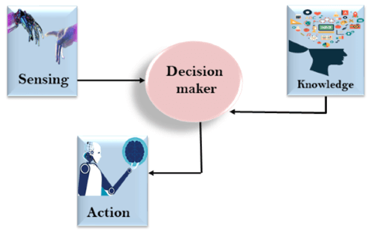
As we can see in the diagram below, there is one decision maker which act by sensing that of the environment and using the knowledge. But if the knowledge part will not present then, it cannot display intelligent behaviour.
Q10) Describe Planning?
A10) What is planning in AI?
- The planning in Artificial Intelligence is about the decision making tasks performed by the robots or computer programs to achieve a specific goal.
- The execution of planning is about choosing a sequence of actions with a high likelihood to complete the specific task.
Blocks-World planning problem
- The blocks-world problem is known as Sussman Anomaly.
- Non Interleaved planners of the early 1970s were unable to solve this problem, hence it is considered as anomalous.
- When two subgoals G1 and G2 are given, a non interleaved planner produces either a plan for G1 concatenated with a plan for G2, or vice-versa.
- In blocks-world problem, three blocks labeled as 'A', 'B', 'C' are allowed to rest on the flat surface. The given condition is that only one block can be moved at a time to achieve the goal.
- The start state and goal state are shown in the following diagram.
Components of Planning System
The planning consists of following important steps:
- Choose the best rule for applying the next rule based on the best available heuristics.
- Apply the chosen rule for computing the new problem state.
- Detect when a solution has been found.
- Detect dead ends so that they can be abandoned and the system’s effort is directed in more fruitful directions.
- Detect when an almost correct solution has been found.
Goal stack planning
This is one of the most important planning algorithms, which is specifically used by STRIPS.
- The stack is used in an algorithm to hold the action and satisfy the goal. A knowledge base is used to hold the current state and actions.
- Goal stack is similar to a node in a search tree, where the branches are created if there is a choice of an action.
The important steps of the algorithm are as stated below:
i. Start by pushing the original goal on the stack. Repeat this until the stack becomes empty. If stack top is a compound goal, then push its unsatisfied subgoals on the stack.
Ii. If stack top is a single unsatisfied goal then, replace it by an action and push the action’s precondition on the stack to satisfy the condition.
Iii. If stack top is an action, pop it from the stack, execute it and change the knowledge base by the effects of the action.
Iv. If stack top is a satisfied goal, pop it from the stack.
Non-linear planning
This planning is used to set a goal stack and is included in the search space of all possible subgoal orderings. It handles the goal interactions by interleaving method.
Advantage of non-Linear planning
Non-linear planning may be an optimal solution with respect to plan length (depending on search strategy used).
Disadvantages of Nonlinear planning
- It takes larger search space, since all possible goal orderings are taken into consideration.
- Complex algorithm to understand.
Algorithm
1. Choose a goal 'g' from the goalset
2. If 'g' does not match the state, then
● Choose an operator 'o' whose add-list matches goal g
● Push 'o' on the opstack
● Add the preconditions of 'o' to the goalset
3. While all preconditions of operator on top of opstack are met in state
● Pop operator o from top of opstack
● State = apply(o, state)
● Plan = [plan; o]
Q11) What do you mean by Learning?
A11) A boolean-valued function defined over a large quantity of training data can be regarded as a concept in Machine Learning. I discussed the principles of constructing a learning system in ML in my previous article, but we still need a learning mechanism or a suitable representation of the target concept to finish the design of a learning algorithm.
Finding the day when my friend Ramesh enjoys his favourite sport, for example, could be one viable target concept. We have some day attributes/features such as Sky, Air Temperature, Humidity, Wind, Water, and Forecast, and we have a target concept named EnjoySport based on these.
The following training example is accessible to you:
Eg | Sky | AirTemp | Humidity | Wind | Water | Forecast | EnjoySport |
1 | Sunny | Warm | Normal | Strong | Warm | Same | Yes |
2 | Sunny | Warm | High | Strong | Warm | Same | Yes |
3 | Rainy | Cold | High | Strong | Warm | Change | No |
4 | Sunny | Warm | High | Strong | Cool | Change | Yes |
Let's use TPE (Task, Performance, Experience) to formally design the problem:
Problem - Looking forward to the day when Ramesh likes his sport.
Task T - Learn to forecast the value of EnjoySport on any given day based on the values of the day's qualities.
Performance measure P - Total proportion of days properly predicted (EnjoySport).
Training experience E - A collection of days with labels (EnjoySport: Yes/No).
Take a look at a very basic hypothesis representation, which is made up of a set of restrictions in the instance attributes. With the help of example I we generate the following hypothesis h i for our training set:
Hi(x):= <x1, x2, x3, x4, x5, x6>
Where x1, x2, x3, x4, x5 and x6 are the values of Sky, AirTemp, Humidity, Wind, Water and Forecast.
Hence h1 will look like(the first row of the table above):
h1(x=1): <Sunny, Warm, Normal, Strong, Warm, Same > Note: x=1 represents a positive hypothesis / Positive example
We're looking for the most appropriate hypothesis to reflect the concept. Ramesh, for example, only participates in his favourite sport on cold, humid days (This seems independent of the values of the other attributes present in the training examples).
h(x=1) = <?, Cold, High, ?, ?, ?>
Here ? indicates that any value of the attribute is acceptable. Note: The most generic hypothesis will be < ?, ?, ?, ?, ?, ?> where every day is a positive example and the most specific hypothesis will be <?,?,?,?,?,? > where no day is a positive example.
We'll go over the two most common methods for coming up with a good hypothesis:
● Find-S Algorithm
● List-Then-Eliminate Algorithm
Q12) Write short notes on Perceptron?
A12) In Machine Learning, we've already learned about the perceptron model.
The perceptron model, the simplest type of artificial neuron networks, resembles a real neuron and uses a hyperplane line to aid with linear binary categorization.
Perceptron models are divided into two categories:
Single Layer Perceptron- The capacity to linearly classify inputs is what distinguishes the Single Layer perceptron. This signifies that this model simply uses a single hyperplane line and classifies the inputs according to previously learnt weights.
Multi-Layer Perceptron- The Multi-Layer Perceptron is distinguished by its capacity to classify inputs using layers. This is a high-performance approach that allows machines to classify inputs simultaneously utilising many layers.
The model's operation is based on the Perceptron Learning Rule, which means that the algorithm can learn the respective coefficients of weights that designate multiple inputs automatically.
The perceptron model registers inputs with the machine and assigns weights based on the coefficients that lead to a certain class for each input. The final value obtained by computing the net sum and activation function at the end stages is used to make this decision.
Let's take a look at a step-by-step approach for understanding how the perceptron model works.
● In the first layer, enter bits of information that will be used as inputs (Input Value).
● All input values and weights (pre-learned coefficients) will be multiplied. All of the supplied values will be multiplied and added.
● In the last stage (activation function/output result), the bias value will shift.
● The weighted input will move on to the activation function stage. Now we'll add the bias value.
● The result obtained will be the output value, which will determine whether or not the output is released.
Q13) What is symbolic?
A13) Symbolic AI is a method of teaching Artificial Intelligence (AI) in the same way as the human brain does. It develops internal symbolic representations of its "reality" as it learns to comprehend it.
Symbols play a critical role in human reasoning and thought. We study both objects and abstract concepts before developing rules to deal with them. These rules can be formalised in a way that reflects common sense.
Symbolic AI imitates this approach by attempting to express human knowledge directly through human-readable symbols and rules that allow for manipulation of those symbols. Symbolic AI is the process of incorporating human knowledge and behavioural rules into computer programmes.
From the postwar era until the late 1980s, symbolic artificial intelligence, sometimes known as Good, Old-Fashioned AI (GOFAI), was the dominant paradigm in the AI field.
Rules engines, expert systems, and knowledge graphs are examples of symbolic reasoning implementations. One of the longer-running examples is Cyc. When you search for something simple like the capital of Germany, Google makes a big one, which is what provides the information in the top box under your query. These systems are nothing more than a jumble of nested if-then statements that draw conclusions about entities (human-readable concepts) and their relationships (expressed in well understood semantics like X is-a man or X lives-in Acapulco).
Consider how Turbotax reflects the US tax code: you tell it how much you made, how many dependents you had, and other factors, and it calculates the tax you owe under the law - that's an expert system.
The role of symbols in artificial intelligence
Symbols are objects that are used to symbolise other objects. Symbols play a critical part in human cognition and thought. If I say I saw a cat up in a tree, your mind will immediately conjure up a picture.
We use symbols to describe things (cat, automobile, plane, etc.) and people all the time (teacher, police, salesperson). Symbols can represent abstract concepts (such as a bank transaction) or non-physical objects (web page, blog post, etc.). They can also be used to describe situations or behaviours (for example, running) (inactive). Hierarchies of symbols can be created (a car is made of doors, windows, tires, seats, etc.). They're also useful for describing other symbols (a cat with fluffy ears, a red carpet, etc.).
One of the most important characteristics of intelligence is the ability to communicate via symbols. As a result, symbols have played an important part in the development of artificial intelligence.
"Every facet of learning or any other trait of intelligence can in principle be so clearly characterised that a machine can be constructed to replicate it," early AI pioneers claimed. As a result, symbolic AI rose to prominence and became the focus of research efforts. Scientists created tools that allowed them to design and manipulate symbols.
Many of the computer science concepts and techniques are the product of these endeavours. The foundation of symbolic AI algorithms is the creation of explicit structures and behaviour rules.
Object-oriented programming is an example of symbolic AI tools. You can define classes, specify their characteristics, and organise them in hierarchies using OOP languages. You can make objects (instances) of these classes and manipulate their properties. Actions, sometimes known as functions, methods, or procedures, can be performed by class instances. Each method runs a set of rules-based instructions that read and modify the characteristics of the current and other objects.
Q14) Write about Sub - symbolic?
A14) Sub-symbolic approaches build correlations between input and output variables, as opposed to symbolic methods, which require human supervision and involvement. These relationships are complex, and they're frequently formalised by functions that map input data to output data or target variables. With Artificial Neural Networks, sub-symbolic approaches describe the Connection is a movement that tries to emulate a human brain and its intricate network of interconnected neurons (ANN). Statistical learning methods such as Bayesian learning, deep learning, back propagation, and genetic algorithms are examples of sub-symbolic AI.
Sub-symbolic methods are more resistant to noise and missing data, and they have a higher computing performance in general. Because they are easy to scale, they are well suited to massive datasets and knowledge networks. Furthermore, they are superior for perception issues and require less advance knowledge.
Connectionist methods, on the other hand, have certain drawbacks. The most important is that these procedures are not interpretable. This poses a significant barrier to their use in sectors where explanations and interpretations are critical. Furthermore, sub-symbolic approaches are frequently limited in important or high-risk decision applications such as medical, legal, or military decision applications, as well as autonomous cars, according to the European Union's General Data Protection Regulation. Furthermore, the training data they handle is extremely important to them.
At first look, this may not appear to be a concern; nonetheless, it prevents users from extrapolating conclusions to unknown cases or data that does not follow the same distribution as the training data. Furthermore, due to the vast number of parameters that must be calculated in sub-symbolic models, they necessitate a lot of computing power and a lot of data. Another issue that arises is the availability of high-quality data for algorithm training, which is often difficult to come by. To avoid biassed results, data must be correctly labelled and have adequate representations of the normal.
Prediction, clustering, pattern classification and recognition of objects, as well as Natural Language Processing (NLP) tasks, are some of the most common uses of sub-symbolic approaches. Text classification and categorization, as well as speech and text recognition, are also seen in sub-symbolic applications.




