Unit – 3
Linked Lists
Each node in singly linked list points to next node and it appears to move in one direction. Thus SLL is unidirectional. Fig. shows schematic diagram of singly linked list with 4 nodes.
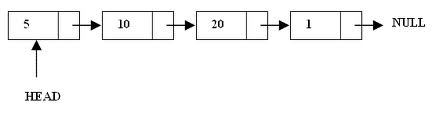
Fig. : Singly Linked List
2. Write a program to create a linked list?
#include <stdio.h>
#include<conio.h>
typedef struct node
{
int data;
struct node *next;
}node;
void main()
{
node *HEAD, *P ;
int n,i;
printf(“Enter no of nodes to be inserted ”)
scanf(“%d”, &n);
HEAD = (node*)malloc(sizeof(node));//get the first node
scanf(“%d”, &(HEAD->data));// get data in first node
HEAD->next= NULL;
P=HEAD;// currently HEAD and P points to same node
for(i=1;i<n;i++)// for n nodes
{
P->next= (node*)malloc(sizeof(node));
P=P->next;
P->next= NULL;
scanf(“%d”, &(P->data));
}
}
Explanation :
Declare node with self referential structure.
Create HEAD node which is first node in Linked List.
HEAD = (node*)malloc(sizeof(node));
Store data in First node .
scanf(“%d”, &(HEAD->data));//
Currently there is only one node in Linked List. So *next contains Null value and HEAD and P points to same node.
HEAD next = NULL;
P = HEAD;
Now create remaining nodes with the help of following code.
for(i=1;i<n;i++)// for n nodes
{
P->next= (node*)malloc(sizeof(node));
P=P->next;
P->next= NULL;
scanf(“%d”, &(P->data));
}
3. Explain traversing in linked list?
Traversing is the most common operation that is performed in almost every scenario of singly linked list. Traversing means visiting each node of the list once in order to perform some operation on that. This will be done by using the following statements.
ptr = head;
while (ptr!=NULL)
{
ptr = ptr -> next;
}
Algorithm
STEP 1: SET PTR = HEAD
STEP 2: IF PTR = NULL
WRITE "EMPTY LIST"
GOTO STEP 7
END OF IF
STEP 4: REPEAT STEP 5 AND 6 UNTIL PTR != NULL
STEP 5: PRINT PTR→ DATA
STEP 6: PTR = PTR → NEXT
[END OF LOOP]
STEP 7: EXIT
C function
#include<stdio.h>
#include<stdlib.h>
void create(int);
void traverse();
struct node
{
int data;
struct node *next;
};
struct node *head;
void main ()
{
int choice,item;
do
{
printf("\n1.Append List\n2.Traverse\n3.Exit\n4.Enter your choice?");
scanf("%d",&choice);
switch(choice)
{
case 1:
printf("\nEnter the item\n");
scanf("%d",&item);
create(item);
break;
case 2:
traverse();
break;
case 3:
exit(0);
break;
default:
printf("\nPlease enter valid choice\n");
}
}while(choice != 3);
}
void create(int item)
{
struct node *ptr = (struct node *)malloc(sizeof(struct node *));
if(ptr == NULL)
{
printf("\nOVERFLOW\n");
}
else
{
ptr->data = item;
ptr->next = head;
head = ptr;
printf("\nNode inserted\n");
}
}
void traverse()
{
struct node *ptr;
ptr = head;
if(ptr == NULL)
{
printf("Empty list..");
}
else
{
printf("printing values . . . . .\n");
while (ptr!=NULL)
{
printf("\n%d",ptr->data);
ptr = ptr -> next;
}
}
}
4. Write a program to search an element using linked list
#include <stdio.h>
#include <stdlib.h>
// Creating node with data and a pointer
struct node {
int data;
struct node *next;
}*head;
void createList(int n);
void search_element(int data);
void displayList();
int main()
{
int n, data, element;
printf("\nEnter the total number of nodes: ");
scanf("%d", &n);
createList(n);
printf("\nThe List is \n");
displayList();
printf("\nEnter the element to be searched in the list : "); // value of the element to be searched in the list
scanf("%d",&element);
search_element(element);
return 0;
}
void createList(int n)
{
struct node *newNode, *temp;
int data, i;
head = (struct node *)malloc(sizeof(struct node));
// When the list is empty
if(head == NULL)
{
printf("Unable to allocate memory.");
}
else
{
printf("\nEnter the data of node 1: ");
scanf("%d", &data);
head->data = data;
head->next = NULL;
temp = head;
for(i=2; i<=n; i++)
{
newNode = (struct node *)malloc(sizeof(struct node));
if(newNode == NULL)
{
printf("Unable to allocate memory.");
break;
}
else
{
printf("\nEnter the data of node %d: ", i);
scanf("%d", &data);
newNode->data = data;
newNode->next = NULL;
temp->next = newNode;
temp = temp->next;
}}}}
void search_element(int data)
{
int count = 0;
struct node* temp;
temp = head;
while(temp != NULL) // Start traversing from head node
{
if(temp -> data == data)
{
printf("\nElement found at position %d",count);
break;
}
else
{
count = count + 1;
temp = temp -> next;
}}
printf("\n Element %d is not found in the list\n",data);
}
void displayList()
{
struct node *temp;
if(head == NULL)
{
printf("List is empty.");
}
else
{
temp = head;
while(temp != NULL)
{
printf("%d\t", temp->data);
temp = temp->next;
}
printf("\n");
}}
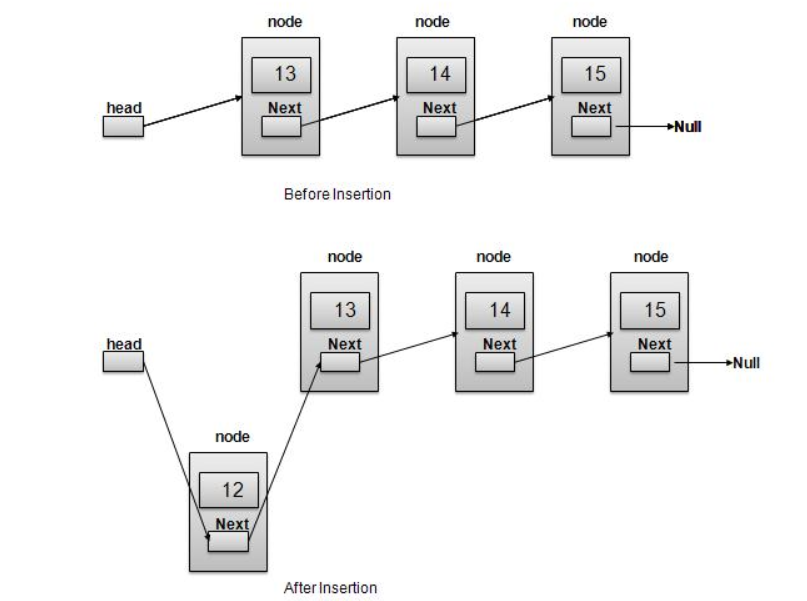
5. Explain insertion in linked list
Insertion is a three- step process −
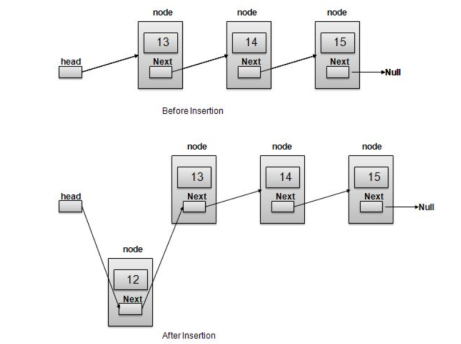
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
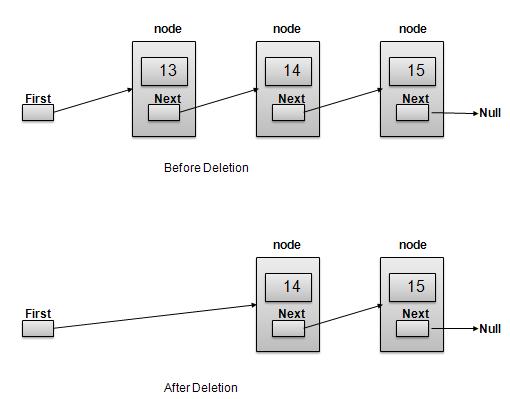
6. Explain deletion in linked list?
Deletion is a two step process −
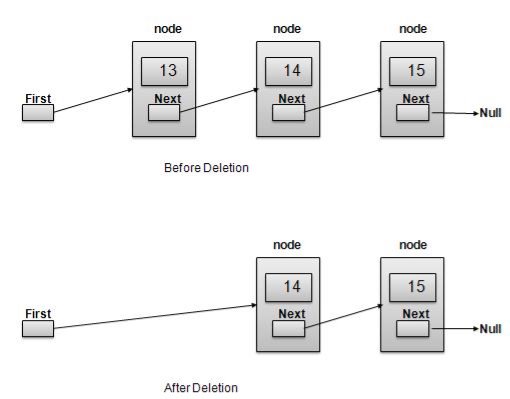
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
7. Explain double ended queue ?
A Double ended queue is a queue in which elements can be inserted or deleted from either front or rear. New elements can be added at either the front or the rear. Likewise, existing items can be removed from either end. This abstract data structure often abbreviated as deque and is also known as head-tail linked list. Deques are useful when we need both random access, and ability to delete/insert at both the ends. This hybrid linear structure provides all the capabilities of stacks and queues in a single data structure.
 DeQueue can be categorized in two types
DeQueue can be categorized in two types
1) Input restricted DeQueue: It allows insertions at only one end
2) output restricted DeQueue: It allows deletions from only one end
8. Write a short note on header node?
A header node is a special node that is found at the beginning of the list. A list that contains this type of node, is called the header-linked list. This type of list is useful when information other than that found in each node is needed.
For example, suppose there is an application in which the number of items in a list is often calculated. Usually, a list is always traversed to find the length of the list. However, if the current length is maintained in an additional header node that information can be easily obtained.
9. Explain types of header linked list
Grounded Header Linked List
It is a list whose last node contains the NULL pointer. In the header linked list the start pointer always points to the header node. start -> next = NULL indicates that the grounded header linked list is empty. The operations that are possible on this type of linked list are Insertion, Deletion, and Traversing.
10. Explain the algorithm analysis of doubly linked list?
There are three ways to analyze an algorithm which are stated as below.
1. Worst case: In worst case analysis of an algorithm, upper bound of an algorithm is calculated. This case considers the maximum number of operation on algorithm. For example if user want to search a word in English dictionary which is not present in the dictionary. In this case user has to check all the words in dictionary for desired word.
2. Best case : In best case analysis of an algorithm, lower bound of an algorithm is calculated. This case considers the minimum number of operation on algorithm. For example if user want to search a word in English dictionary which is found at the first attempt. In this case there is no need to check other words in dictionary.
3. Average case : In average case analysis of an algorithm, all possible inputs are consider and computing time is calculated for all inputs. Average case analysis is performed by summation of all calculated value which is divided by total number of inputs. In average case analysis user must be aware about the all types of input so average case analyses are very rarely used in practical cases.
11. Explain circular linked list complexity?
Complexity of an algorithm is the function which gives the running time and space requirement of an algorithm in terms of size of input data. Frequency count refers to the number of times particular instructions executed in a block of code. Frequency count plays important role in the performance analysis of an algorithm. Each instruction in algorithm is incremented by one as its execution. Frequency count analysis is the form of priori analysis. Frequency count analysis produces output in terms of time complexity and space complexity.
Time complexity : Time complexity is about to number of times compiler execute basic operations in instruction. That is because basic operations are so defined that the time for the other operations is much less than or at most proportional to the time for the basic operations. To determine time complexity user need to calculate frequency count and express it in terms of notations. Total time taken by program is the summation of compile time and running time. Out of these two main point to take care about is running time as it depends upon the number and magnitude of input and output.
Space complexity : Space complexity is about to maximum amount of memory required for algorithm. To determine space complexity user need to calculate frequency count and express it in terms of notations.




