UNIT- 5
Filters using Regular Expressions
Grep: Global Regular Expression Print. The grep command searches for a pattern of characters in a file or multiple files. If the pattern contains white space, it must be quoted. The pattern is either a quoted string or a single word, and all other words following it are treated as filenames. Grep sends its output to the screen and does not change or affect the input file in any way.
Syntax: grep (option]patters (files] grep Tom /etc/passwd Option: -b: Display the block number at the beginning of each line. -I: Ignore case sensitivity -n: Display the matched lines and their line numbers -s: Silent mode. |
Explanation:
Grep will search for the pattern Tom in a file called letc/passed. If successful, the line from the file will appear on the screen; if the pattern is not found, there will be no output at all, and if the file is not a legitimate file, an error will be sent to the screen. If the pattern is found, grep returns an exit status of 0, indicating success; if the pattern is not found, the exit status returned is 1; and if the file is not found, the exit status is 2. The grep program can get its input from a standard input or a pipe, as well as from files. If we forget to name a file, grep will assume it is getting input from standard input, the keyboard, and will stop until we type something. If coming from a pipe, the output of a command will be piped as input to the grep command, and if a desired pattern is matched, grep will print the output to the screen.
%ps –ef | grep root
The output of the ps command (ps -ef displays all processes running on this system) is sent to grep and all lines containing root are printed.
The grep command supports a number of regular expression meta-characters to help further define the search pattern. It also provides a number of options to modify the way it does its search or displays lines. For example, we can provide options to turn off case-sensitivity, display line numbers, display errors only, and so on.
% grep -n '^jack:' /etc/passwd
Grep searches the /etc/passwd file for jack ; if jack is at the beginning of a line, grep prints out the number of the line on which jack was found and where in the line jack was found.
Egrep: egrep is an acronym that stands for "Extended Global Regular Expressions Print". The 'E' in egrep means treat the pattern as a regular expression. "Extended Regular Expressions" abbreviated 'ERE' is enabled in egrep. egrep (which is the same as grep -E) treats +, ?, |, (, and) as meta-characters.
In basic regular expressions (with grep), the meta-characters 2.1.1 and ) lose their special meaning. If we want grep to treat these characters as meta-characters, escape them \ ? ,\+, \},\|,\( and \).
For example, here grep uses basic regular expressions where the plus is treated literally, any line with a plus in it is returned.
grep "+" myfile.txt
egrep on the other hand treats the "+" as a meta character and returns every line because plus is interpreted as "one or more times".
egrep "+" myfile.txt
Here every line is returned because the + was treated by egrep as a meta character. normal grep would have searched only for lines with a literal +
Fgrep: fgrep is an acronym that stands for "Fixed-string Global Regular Expressions Print". fgrep (which is the same as grep -F) is fixed or fast grep and behaves as grep but does NOT recognize any regular expression meta-characters as being special The search will complete faster because it only processes a simple string rather than a complex pattern.
For example, if I wanted to search my bash profile for a literal dot (.) then using grep would be difficult because I would have to escape the dot because dot is a meta character that means 'wild-card, any single character':
grep "." myfile.txt
The above command returns every line of myfile.txt. Do this instead:
fgrep "." myfile.txt
Then only the lines that have a literal in them are returned. fgrep helps us not bother escaping our meta characters.
Pgrep: pgrep is an acronym that stands for "Process-ID Global Regular Expressions Print" pgrep looks through the currently running processes and lists the process IDs which matches the selection criteria to stdout. pgrep is handy when all you want to know is the process id integer of a process. For example, if I wanted to know only the process ID of my mysql process I would use the command pgrep mysql which would return a process ID like 7312.
|
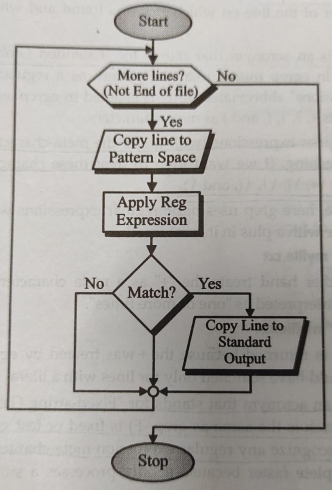
Figure 1
Limitations of grep:
1. grep cannot be used to add, delete, or change a line.
2. grep cannot be used to print only part of a line.
3. grep cannot read only part of a line.
4. grep cannot select a line based on the contents of the previous or the next line. There is only one buffer and its holds only the current line.
S.no | Meta-character | Function | Example | What it matches |
1 | ^ | Beginning of line anchor | ‘^litchie’ | Matches all lines beginning with litchie. |
2 | $ | End of line character | ‘litchie$’ | Matches all lines ending with litchie. |
3 | . | Matches one character | ‘I..e’ | Matches lines containing an l, followed by two characters, followed by an e. |
4 | * | Matches zero or more characters | ‘*litchie’ | Matches lines with zero or more spaces, of the preceding characters followed by the pattern litchie |
5 | [] | Matches one character in the set | ‘[L1]itchie’ | Matches lines containing litchi or Litchie. |
6 | [^] | Matches one character not in the set | ‘[^A-K]itchie’ | Matches lines not containing A through K followed by itchie |
7 | \< | Beginning of word anchor | ‘\<litchie’ | Matches lines containing a word that begins with litchie. |
8 | \> | End of word anchor | ‘litchie\>’ | Matches lines containing a word that ends with litchie. |
9 | \(..\) | Tags matched characters | ‘(love\)ing’ | Tags marked portion in register to be remembered later as number 1. To reference later, use \1 to repeat the pattern. May use up to nine tags. starting with the first tag at the leftmost part of the pattern. For example, the pattern love is saved in register 1 to be referenced later as \1. |
10 | x\{m\} x\{m,\} x\{m,n\} | Repetition of character x, m times, at least m times, or between m and n times | 'o \{5\}’ 'o\{5,\}’ 'o\{5,10\}’
| Matches if line has 5 o's, at least 5 o's, or between 5 and 10 o's |
Grep options: The grep command has a number of options that control its behavior. Not all versions of UNIX support exactly the same options, Option Description -b Precedes each line by the block number on which it was found. This is sometimes useful in locating disk block numbers by context -c Displays a count of matching lines rather than displaying the lines that match. -h Does not display filenames. -I Ignores the case of letters in making comparisons (i.e., upper and lowercase are considered identical). -l Lists only the names of files with matching lines (once), separated by newline characters. -n Precedes each line by its relative line number in the file. -s Works silently, that is, displays nothing except error messages. This is useful for checking the exit status. -v Inverts the search to display only lines that do not match. -w Searches for the expression as a word, as if surrounded by \< and \> This applies to grep only. (Not all versions of grep support this feature; e.g, SCO UNIX does not.) % cat datafile 101 | Amit Sharma |Unix |767|12-08-1983 102 | Binay Pandey |DBMS |575|01-07-1984 103 |Diwakar ghosh |Unix |667|17-06-1985 104 |Harry Bose |Unix |766|29-05-1987 105 |Ishanvi Agarwal |ADA |876|23-05-1988 106 |Nabonita Sarkar |ADA |761|11-04-1989 107 | Poonam Bhawnani |JAVA |687|07-03-1983 108 | Rosesh Sarabhai |MP |666|06-01-1986 109 | Sarika Sar |JAVA |777|10-04-1986 110 | Yogesh Dilliwar |Unix |888|12-04-1987 grep -n 'JAVA' datafile 7:107 | Poonam Bhaw |JAVA |687|07-03-1983 9:109 | Sanika Sar |JAVA |777|10-04-1986 The -n option precedes each line with the number of the line where the pattern was found, followed by the line. grep -i 'san' datafile 109 | Sanika Sar | JAVA | 777 | 10-04-1986 The -i option turns off ease-sensitivity. It does not matter if the expression pat contains any combination of uppercase or lowercase letters. grep -'Sar' datafile 101 | Amit Sharma |Unix |767|12-08-1983 102 | Binay Pandey |DBMS |575|01-07-1984 103 |Diwakar ghosh |Unix |667|17-06-1985 104 |Harry Bose |Unix |766|29-05-1987 105 |Ishanvi Agarwal |ADA |876|23-05-1988 107 | Poonam Bhawnani |JAVA |687|07-03-1983 110 | Yogesh Dilliwar |Unix |888|12-04-1987 Prints all lines not containing the pattern Sar. This option is used when deleting a specific entry from the input file. To really remove the entry, we would redirect the output of grep to a temporary file, and then change the name of the temporary file back to the name of the original file as: grep -v 'Sar' datafile > temp mv temp datafile We must use a temporary file when redirecting the output from datafile. If we redirect from datafile to datafile, the shell will "clobber" the datafile. Grep-|'ADA'* datafile datebook The option -l causes grep to print out only the filenames where the pattern is found instead of the line of text. grep -'Sar datafile 3 The-c option causes grep to print the number of lines where the pattern was found. This does not mean the number of occurrences of the pattern. For example, if west is found three times on a line, it only counts the line once. grep –w 'Sar’ datafile 109 | Sanika Sar |JAVA |777 | 10-04-1986 The -w option causes grep to find the pattern only if it is a word, not part of a word. Only the line containing the word sar is printed, not sarkar, sarabhai, and so forth. |
SED: Sed is an acronym for stream editor. Although the name implies editing it is not a true editor it does not change anything in the original file. Rather sed scans the input file, line by line, and applies a list of instructions (called a sed script) to each line in the input file.
Syntax :
$ sed [option] 'address action/command' filename
The script which is usually a separate file can be included in the sed command line if it is a one-line command. Each line in the input file is given a line number by sed. This number can be used to address lines in the text.
For each line, sed performs the following operations:
1. Copies an input line to the pattern space. The pattern space is a special buffer capable of holding one or more text lines for processing.
2. Applies all the instructions in the script, one by one, to all pattern space lines that match the specified addresses in the instruction.
3. Copies the contents of the pattern space to the output file unless directed not to by the -n option flag.
SED Flow chart
|
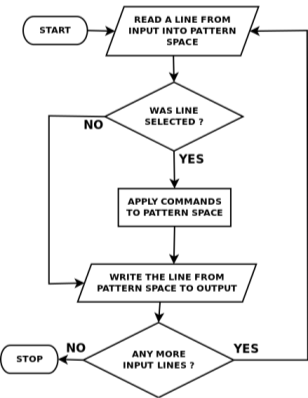
Figure 2
When all of the commands have been processed, sed repeats the cycle starting with 1.
In the overall process there are two loops in this processing cycle.
(i) One loop process all of the instructions against the current line (operation 2 in the list). The second loop processes all lines.
(ii) A second buffer, the hold space, is available to temporarily store one or more lines as directed by the sed instructions.
Internal commands: There are 25 commands that can be used in an instruction. We group them into nine categories based on how they perform their task. Figure summarizes the command categories.
- Line Number
- Modify
- Substitute
- Transform
- Input/Output
- Files
- Branch
- Hold Space
- Quit
The line number command (=) writes the current line number at the beginning of the line when it writes the line to the output without affecting the pattern space. It is similar to the grep -n option. The only difference is that the line number is written on a separate line $ sed '=' datafile 1 101 | Amit Sharma |Unix |767|12-08-1983 2 102 | Binay Pandey |DBMS |575|01-07-1984 3 103 |Diwakar ghosh |Unix |667|17-06-1985 4 104 |Harry Bose |Unix |766|29-05-1987 5 105 |Ishanvi Agarwal |ADA |876|23-05-1988 6 106 |Nabonita Sarkar |ADA |761|11-04-1989 7 107 | Poonam Bhawnani |JAVA |687|07-03-1983 8 108 | Rosesh Sarabhai |MP |666|06-01-1986 9 109 | Sarika Sar |JAVA |777|10-04-1986 10 110 | Yogesh Dilliwar |Unix |888|12-04-1987 If we print only the line number of lines containing the pattern Unix. To do this, we must use the-n option, which turns off the automatic printing. $ sed -n '/Unix/=' data file 1 3 4 10
2. Modify Command: It is used to insert, append, change, or delete one or more whole lines. The modify commands require that any text associated with them be placed on the next line in the script. Therefore, the script must be in a file; it cannot be coded on the shell command line. a. Insert (i): Insert adds one or more lines directly to the output before the address. This command can only be used with the single line and a set of lines; it cannot be used with a range $ sed '1i\ need to use \ before hit the enter key >#include<stdio.h>\ >#include<conio.h> >' fact.c > $$ redirect to temporary file The example inserts text at line number 1.Each line except the last line has to be terminated by the \ before hitting the enter key. b. Append(a): Append is similar to the insert command except that it writes the ten directly to the output after the specified line. Like insert, append cannot be used with a range address. Inserted and appended text never appears in sed's pattern space. They are written to the output before the specified line (insert) or after the specified line (append), even if the pattern space is not itself written. Because they are not inserted into the pattern space, they cannot match a regular expression, nor do they affect sed's internal line counter, c. Change (c): Change replaces a matched line with new text. Unlike insert and append, it accepts all four address types. d. Delete Pattern Space Command (d): The delete command comes in two versions When a lowercase delete command (d) is used, it deletes the entire pattern space Any script commands following the delete command that also pertain to the deleted text are ignored because the text is no longer in the pattern space. $ sed ‘/ ADA /d' datafile > newdatafile It will select all lines except those containing ADA and saves them in to newdatafile. e. Delete Only First Line Command (D): When an uppercase delete command (D) is used, only the first line of the pattern space is deleted. Of course, if the only line in the pattern space, the effect is the same as the lowercase delete.
3. The Substitute (s) Command: The syntax of the s (as in substitute) command is: $ sed 's/regexp/replacement/flags’ The characters may be uniformly replaced by any other single character within any given s command. The character (or whatever other character is used in its stead) can appear in the regexp or replacement only if it is preceded by a /character. The s command is probably the most important in sed and has a lot of different options. Its basic concept is simple: the s command attempts to match the pattern space against the supplied regexp; if the match is successful, then that portion of the pattern space which was matched is replaced with replacement. $sed 's/|/:/’ datafile | head -2 101 | Amit Sharma |Unix |767|12-08-1983 102 | Binay Pandey |DBMS |575|01-07-1984 The replacement can contain \n (n being a number from 1 to 9, inclusive) references which refer to the portion of the match which is contained between the nth \(and its matching \). Also, the replacement can contain unescaped & characters which reference the whole matched portion of the pattern space. Finally, as a GNU sed extension we can include a special sequence made of a backslash and one of the letters L, 1, U, u, E. The meaning is as follows: \L-Turn the replacement to lowercase until a \U or \E is found, \1 - Turn the next character to lowercase, \U-Turn the replacement to uppercase until a \L or \E is found, \u- Turn the next character to uppercase, \E-Stop case conversion started by \L or \U.
To include a literal \, &, or newline in the final replacement, be sure to precede the desired \, &, or newline in the replacement with a The s command can be followed by zero or more of the following flags: g - Apply the replacement to all matches to the regexp, not just the first. In the example only the first instance of I has been replaced. If we want to replace all the instances of | then we will use g flag. $ sed 's/|/:/g' datafile|head -2 101 | Amit Sharma |Unix |767|12-08-1983 102 | Binay Pandey |DBMS |575|01-07-1984 (a) Number - Only replace the numberth match of the regexp. (b) P-If the substitution was made, then print the new pattern space. (c) w file-name = If the substitution was made, then write out the result to the named file. As a GNU sed extension, two special values of file-name are supported: /dev/stderr, which writes the result to the standard error, and /dev/stdout, which writes to the standard output. (d) e - This command allows one to pipe input from a shell command into pattern space. If a substitution was made, the command that is found in pattern space is executed and pattern space is replaced with its output. A trailing newline is suppressed; results are undefined if the command to be executed contains a nul character. This is a GNU sed extension. (e) I or i - The I modifier to regular-expression matching is a GNU extension which makes sed match regexp in a case-insensitive manner. (f) M or m - The M modifier to regular-expression matching is a GNU sed extension which causes ^ and $ to match respectively the empty string after a newline, and the empty string before a newline. There are special character sequences (\‘and \’) which always match the beginning or the end of the buffer. M stands for multi line. 4. Transform Command (y): It is sometimes necessary to transform one set of characters to another. For example, IBM mainframe text files are written in a coding system known as Extended Binary Coded Decimal Interchange Code (EBCDIC). In EBCDIC, the binary codes for character are different from ASCII. To read an EBCDIC file, therefore, all characters must be transformed to their ASCII equivalents as the file is read. The transform command (y) requires two parallel sets of characters. Each character in the first string represents a value to be changed to its corresponding character in the second string. $ sed 'y/Unix/UNIX/' datafile | head -2 101 | Amit Sharma |Unix |767|12-08-1983 102 | Binay Pandey |DBMS |575|01-07-1984 5. Input and Output Commands: The sed utility automatically reads text from the input file and writes data to the output file, usually standard output. The input and output command is used to control the input and output more properly. There are five input/output commands: (i) next (n), (ii) append next (N), (iii) print (p) (iv) print first line (P). (v) list (l).
(i) Next Command (n): The next command (n) forces sed to read the next line from the input file. Before reading the next line, however, it copies the current contents of the pattern space to the output, deletes the current text in the pattern space, and then refills it with the next input line. After reading the input line, it continues processing through the script.
$ cat numfile one [Blank line] two [Blank line] three [Blank line] four $ sed 'n >/^$/d' datafile one two three four
(ii) Append Next Command (N): Whereas the next command clears the pattern space before inputting the next line, the append next command (N) does not Rather, it adds the next input line to the current contents of the pattern space. This is especially useful when we need to apply patterns to two or more lines at the same time. To demonstrate the append next command, we create a script that appends the second line to the first, the fourth to the third, and so on until the end of the file. $ sed 'N > s/\n//’ datafile one two three four (iii) Print Command (p): The print command (p) copies the current contents of the pattern space to the standard output file. If there are multiple lines in the pattern space, they are all copied. The contents of the pattern space are not deleted by the print command. $ sed 3p' numfile one
two two
three four (iv) Print First Line Command (P): Whereas the print command prints the entire contents of the pattern space, the print first line command (p) prints only the first line. That is, it prints the contents of the pattern space up to and including a newline character. Any text following the first newline is not printed.
(v) List Command (1): Depending on the definition of ASCII, there are either 128 (standard ASCII) or 256 (extended ASCII) characters in the character set. Many of these are control characters with no associated graphics. Some, like the tab, are control characters that are understood and are actually used for formatting but have no graphic. Others print as spaces because a terminal doesn't support the extended ASCII characters. The list command (1) converts the unprintable characters to their octal code.
sed -n ‘I' numfile one$ $ two$ $ three$ $ Four$ note: $ indicates new line character
6. File Commands: There are two file commands that can be used to read and write files. There must be exactly one space between the read or write command and the filename. This is one of those sed syntax rules that must be followed exactly.
(i) Read File Command (r): The read file command reads a file and places its contents in the output before moving to the next command. It is useful when we need to insert one or more common lines after text in a file. The contents of the file appear after the current line (pattern space) in the output. $ cat letterhead To The Branch Manager Malviya Road Branch Raipur, 492001
$ cat signa Sincerely yours, V.V.S.R Sudhakar Unix consultants Inc
$ cat readfile.sed 1 r letterhead $ r signa
$ sed -f readfile.sed inputfile To The Branch Manager Malviya Road Branch Raipur, 492001
Sir/Madam, ……………………………… ………………………………………… ………………………………………… Sincerely yours, V.V.S.R Sudhakar Unix consultants Inc
(ii) Write File Command (w): The write file command (w) writes (actually appends) the contents of the pattern space to a file. It is useful for saving selected data to a file
7. Branch Commands: The branch commands change the regular flow of the commands in the script file Recall that for every line in the file, sed runs through the script file applying commands that match the current pattern space text. At the end of the script file, the text in the pattern space is copied to the output file, and the next text line is read into the pattern space replacing the old text Occasionally, we want to skip the application of the commands. The branch commands allow us to do just that, skip one or more commands in the script file. There are two branch commands: (i) branch (b). (ii) branch on substitution (t).
Branch Label: Each branch command must have a target, which is either a label or the last instruction in the script (a blank label). A label consists of a line that begins with a colon (: ) and is followed by up to seven characters that constitute the label name There can be no other commands or text on the script-label line other than the colon and the label name. The label name must immediately follow the colon: there can be no space between the colon and the name, and the name cannot have embedded spaces. An example of a label is: : comHere (i) Unconditional branch command (b): The branch command (b) follows the normal instruction format consisting of an address, the command (b), and an attribute (target) that can be used to branch to the end of the script or to a specific location, within the script. The target must be blank or match a script label in the script. If no label is provided the branch is to end of the script (after the last line) at which point the current contents of the patter space are copied to the output file and the script is repeated for the next input line. Syntax: $sed: label commands (s) b label. Label: Specification of label Commands: Any sed command (s). Label: Any name for the label b label : Jumps to the label without checking any conditions. If label is not specified, then jumps to the end of the script.
Example: Replace the first occurrence of a pattern in a whole file. In the file the geek stuff tool replace the first occurrence of "administration" to "supervision". $ sed [administration | {s| administration | supervision| :loop n b loop } thegeekstufftxt Linux Supervision scripting Tips and Tricks Windows Administration Database Administration of oracle Administration of mysql Security Network Online Security Productivity Google search 1 Tips "web based time tracking Web based to do list and Reduce key stress etc"
(ii) Conditional branch command (t): The branch command is unconditional whereas branch on substitution (t) command is conditional. For example we may need to branch only if a substitution has been made. It is also known as the test command. Its format is the same as basic branch command. Syntax: $ sed’: label command (s) t Label’ Label: Specification of label Command: Any sed command (s) Label : Any name for the label t label : Jumps to the label only if label is not specified then jumps to the end of the script. Example: If a line ends with a backslash append the next line to it. $sed : loop /\\$/N $/\\\n*// t loop thegeekstuff.txt Linux Administration Scripting Tips and tricks Windows Administration Database Administration of oracle Administration of mysql Security Network Online security Productivity Google search tips "web based time tracking Web based to do list and Reduce key stores etc"
8. Hold Space Commands: It is used to save the pattern space. There are five commands that are used to move text back and forth between the pattern space and the hold space:
9. Quit command: The quit command (q) terminates the sed utility. $ sed ‘3q' datafile 101 | Amit Sharma |Unix |767|12-08-1983 102 | Binay Pandey |DBMS |575|01-07-1984 103 |Diwakar ghosh |Unix |667|17-06-1985 It will print 3 lines from the file and quit from sed.
|
References
- Sumitabha Das: UNIX – Concepts and Applications, 4th Edition, Tata McGraw Hill, 2006.
- Behrouz A. Forouzan and Richard F. Gilberg: UNIX and Shell Programming, Cengage Learning, 2005.
- M.G. Venkateshmurthy: UNIX & Shell Programming, Pearson Education, 2005.




