Unit - 6
Applications
Knowing and adhering to this classification will benefit you and your business at every stage of the ML model cycle.
Here are five ways that a machine learning algorithm (sometimes referred to as "AI" below) can interact with people.
● AI decides and implements (“automator” scheme) — Because it is assumed that involving people will simply slow down the process in this type of contact, the ML algorithms do practically all of the work. They need to be able to see all of the facts and context. Clearance price for unsold and soon-to-expire inventory, as well as individualised customer discounts, are two examples of situations when this technique may be acceptable.
● AI decides, Human implements (“decider” scheme) — Humans will implement the retained solution once AI captures the context and makes the decisions. If a customer selects out-of-stock products while buying online, an ML algorithm can utilise historical data to propose alternatives. Before they are delivered, humans can inspect the quality of the proposals. Another example is when an AI algorithm detects faults in manufacturing facilities, and then a person does the repair. This type is known as a Decider.
● AI recommends, Human decides (“recommender” scheme) — With Google Maps, an AI computer suggests several routes to a destination, and a human selects the best one. Another example is an AI programme that can recommend what products to buy to replenish a grocery shop's stock; if the algorithm lacks access to the supply chain, the store manager will make the final ordering decision.
● AI generates insights, Human does decision making (“illuminator” scheme) — The creative side of humans is aided by AI insights. For example, a grocery chain's AI programme may analyse buying patterns particular to various geographic locations and utilise them to make recommendations to merchants about prospective location-specific features. Another example is that an AI system might reveal future labour requirements, which HR professionals can use to gain a competitive advantage.
● Human generates, AI evaluates (“evaluator” scheme) — In every previous situation, the information flowed from AI to humans. In this case, we reverse the process: humans propose hypotheses, and AI tests them. The most prominent example is "digital twins" technology, in which employees at a corporation create a large number of scenarios based on a digital model of an asset (such as a manufacturing plant), and AI subsequently simulates and evaluates those situations. Other uses of the evaluator system include testing uncommon scenarios, such as examining the impact of a pandemic like Covid-19 on internet commerce, or assessing the impact of hurricanes using historical data on disaster relief agencies.
All five modalities discussed above are incorporated into the business operations of organisations that successfully employ ML to generate growth. It is critical for effective user testing and successful integration of machine-learning processes into corporate operations for ML practitioners to understand which of the five schemes is being used in each situation.
Predictive maintenance is a term used in AI and machine learning to describe the capacity to use large amounts of data to identify and address potential issues before they lead to failures in operations, processes, services, or systems. Having robust predictive maintenance technologies in place allows businesses to foresee when and where potential service breakdowns may occur, and move quickly to respond in order to avoid service interruptions.
Why Is Predictive Maintenance Important?
Predictive maintenance services assist firms to keep essential assets running for as long as possible, ensuring that systems stay up and running. Instead of reacting to issues as they happen, firms may use their existing data to get ahead of future failures or disruptions and solve them proactively. This includes the following:
● Cost savings are achieved by avoiding unplanned downtime, redundant inspections, and inefficient preventative maintenance. Increased productivity and lower labour and material costs result in cost savings.
● Improved performance and longer equipment life result in lower equipment lifetime costs.
● Higher quality, less rework, fewer faults, improved safety, and increased energy efficiency are all indirect benefits.
Predictive maintenance solutions, according to McKinsey, may minimise industrial machine downtime by 30 to 50 percent while also increasing machine life by 20 to 40 percent. Manufacturers can also improve their operations and maintain the integrity of their supply networks.
In several sectors, preventive maintenance is part of the normal maintenance process. Preventive maintenance based on data-driven analytics has been used for years in trains and aircraft, for example. The signals from the attached sensors are tracked in these industries in order to assess system health and provide appropriate support. Furthermore, using an analytics engine to organise and analyse sensor data provides a historical examination of typical failures, system difficulties, and timeliness.
While these data-driven insights and machine test results aid in the implementation of the same maintenance programmes for many systems in an environment, they also aid in the establishment of a standard maintenance timeline, as well as resource usage and cost reduction.
Health management
It's not surprising that today's AI and ML hoopla is accompanied by high hopes and expectations, but actual implementations and deployments in clinical practise remain a pipe dream. One explanation for this is the divide that exists between the controlled sandbox in which algorithm development takes place and the clinical desert in which healthcare takes place.
The transition from the algorithm development sandbox to the clinical wilderness is fraught with difficulties:
1. Providing and demonstrating clinical value
2. Accessing relevant training data
3. Building user-friendly AI/ML applications
4. Deployment and integration with clinical workflows
Providing and demonstrating clinical value
To create algorithms that will be employed in clinical care, developers/researchers must concentrate on issues that are important to end users (healthcare professionals), end users' management, or end users' customers (the patients). Will the algorithm, for example, make physicians more efficient or even more effective, or will it allow physicians to provide care that was previously unavailable?
Accessing relevant training data
"Data is the new oil!" says the narrator. " We've all heard it, and it's especially true in machine learning, where data access is critical when training new algorithms. In terms of open access and making medical picture data available, a lot has transpired in the last decade. For example, anyone looking for medical picture data to train their algorithms might check into the Cancer Imaging Archive or Grand Challenges in Biomedical Image Analysis.
These sources, however, can only take you so far because the data is often constrained in terms of sample size and sources. As a result, establishing access to other data sources is critical to ensuring the robustness of any trained algorithm.
Building user-friendly applications
A poorly designed user interface can render a good algorithm useless, and a well-designed user interface can transform a mediocre algorithm into a powerful tool. Another consideration is that algorithms are not infallible. As a result, user-friendly AI systems that ensure that false predictions are quickly identified and dealt with are critical, particularly in the healthcare industry.
Deployment and integration with clinical workflows
Healthcare IT is no longer what it was decades ago. Today's healthcare IT is a lot more standardised, with a lot more security protocols in place, which is wonderful, but it makes it tough to implement new AI applications, especially for non-established businesses. What kind of hardware and software will be required to execute the application? Is the app going to be on-premises or in the cloud? What is the procedure for gaining access to protected health information? Who is going to have access to this data? These are just a few of the questions that the healthcare IT team will ask.
Diagnosis and treatment applications
Since the 1970s, when MYCIN was created at Stanford to diagnose blood-borne bacterial infections, AI has been focused on disease diagnosis and therapy. 8 Although these and other early rule-based systems showed promise in terms of effectively identifying and treating disease, they were not accepted into clinical practise. They were not significantly better than human diagnosticians, and their workflows and medical record systems were poorly connected.
More lately, IBM's Watson has gotten a lot of press for its emphasis on precision medicine, especially cancer diagnosis and treatment. Watson uses a combination of machine learning and natural language processing. Customers realised how difficult it was to train Watson how to address certain types of cancer9 and integrate Watson into care processes and systems, thus early enthusiasm for this application of the technology diminished.
Patient engagement and adherence applications
Patient involvement and adherence have long been seen as healthcare's 'last mile' difficulty – the ultimate barrier between ineffective and good health outcomes. The better the outcomes — utilisation, financial outcomes, and member experience – the more patients actively participate in their own well-being and treatment. Big data and AI are increasingly being used to address these issues.
Clinical experience is frequently used by providers and hospitals to establish a plan of care that they know will improve the health of a chronic or acute patient. That doesn't matter if the patient doesn't make the necessary behavioural changes, such as losing weight, arranging a follow-up visit, filling medicines, or adhering to a treatment plan. Noncompliance, or when a patient fails to follow a treatment plan or take prescription medications as directed, is a big issue.
Administrative applications
In healthcare, there are numerous administrative applications. In comparison to patient care, the use of AI in this domain has a lower potential for revolution, but it can nevertheless deliver significant efficiencies. These are required in healthcare since the average US nurse, for example, spends 25% of her time on regulatory and administrative tasks. RPA is the technology that is most likely to be applicable to this goal. It has a wide range of healthcare applications, including claims processing, clinical documentation, revenue cycle management, and medical records management.
Chatbots have also been used by some healthcare organisations for patient interaction, mental health and wellness, and telehealth. Simple transactions, such as refilling medicines or booking appointments, may benefit from these NLP-based applications.
Key takeaway
Predictive maintenance is a term used in AI and machine learning to describe the capacity to use large amounts of data to identify and address potential issues before they lead to failures in operations, processes, services, or systems.
One of the most important aspects of quality assurance is fault detection. Fault detection is essential for reducing software development time and cost. Despite the fact that there are numerous detection approaches available in software engineering, a constant software defect detection methodology is required. The four techniques of machine learning are discussed: supervised, unsupervised, semi-supervised, and reinforcement learning. According to the report, a combination of classification and reduction machine learning algorithms were used to find the issue.
Machine Learning approaches are a set of algorithms for determining the mapping of (X, Y) in order to generate a forecast of Y for a new X. It's written as Y=f (X). The core notion behind machine learning is that it parses data, determines what can be learned from it, and then applies what it has learned to make well-informed decisions.
The diagram (below) depicts the essential operations of a fault management system and how they relate to one another.
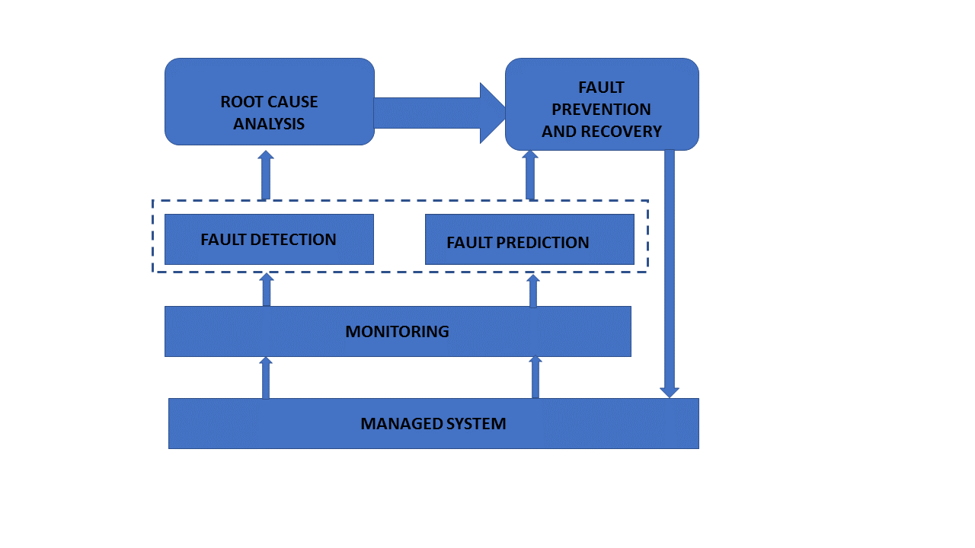
Fig: Operation of fault management
Sensors are gradually being added to industrial systems, such as the Internet of Things (IoT), to collect information on the items they supply. Managing all of this data in order to apply solutions in real-time enables for benefits to be extended throughout a more precise maintenance process (for example, boilers, which are self-propelled and widely used in industries such as healthcare, agriculture, cement, pharmaceuticals, and so on). The earliest detection of the defect may confirm the consistency and safety of business processes, reducing the likelihood of unforeseen failures.
Because of the increasing complexity of modern systems and the amount of data generated, fault detection algorithms typically have limits.
A. DESCRIPTIVE ANALYTICS - Compare the information obtained from an item to historical data to determine whether it is performing properly.
B. DIAGNOSTIC ANALYTICS - Determine the source of the problem. This procedure should take into account health-related trends as well as the operational setting.
C. PREDICTIVE ANALYTICS - Predict the state of the item in the future to catch any potential problems early.
D. PRESCRIPTIVE ANALYTICS - To reduce fault, develop detailed maintenance schedules based on previous projections.
Key takeaway
Fault detection is essential for reducing software development time and cost. Despite the fact that there are numerous detection approaches available in software engineering, a constant software defect detection methodology is required
Nonlinearity must be taken into account while examining and assessing the status of dynamical systems. Previously computationally infeasible investigations are now easily executable on standard computer hardware thanks to recent improvements in computation. However, computing expense remains an issue in some applications, such as uncertainty quantification or high precision real-time simulation. This involves the use of reduced-order modelling techniques, which can help to minimise the computational burden of nonlinear analysis.
We propose a reduction strategy based on the use of an autoencoder to infer a latent space from output-only response data. This latent space serves as an invertible reduction basis for the nonlinear system, as it approximates the system's nonlinear normal modes (NNMs). In the reduced space, the suggested machine learning framework is then supplemented by the usage of long short-term memory (LSTM) networks. These are used to develop a nonlinear reduced-order model (ROM) of the system that can recreate the whole dynamic response of the system under a known driving input.
Solving partial differential equations (PDE) is a difficult task that is frequently forced to be done numerically due to a lack of better analytical options. To create a high-quality numerical approximation, one must select the suitable method and its parameters based on the problem to be solved. This results in expensive computations in terms of memory allocation (ne spatial grids) and computation time (short timesteps); additionally, some applications, like as weather prediction, necessitate further adjustment to drive the prediction to reflect the real data.
To reduce these hazards and speed up the solutions, several approaches known as Model Order Reduction are used to reduce the inecient numerical issue into a smaller one that can be solved faster and produce similar quality results (MOR). The so-called Proper Orthogonal Decomposition is one example (POD).
However, in recent years, Deep Learning has emerged as a strong tool for solving a wide range of issues, ranging from image classification to self-driving cars. The typical approach is to take a set of real data and construct a representation of it that can accurately predict some characteristic of a new future set. So, instead of dierential equations, one viable methodology for controlling the aforementioned physical difficulties is to employ real data, i.e., a data-driven solution. Deep Learning, particularly Neural Networks (NN), has the advantage of being able to deal with non-linear issues and, once trained, producing a new prediction from a batch of data is incredibly fast.
However, an alternate strategy, conceptually similar to MOR techniques, is to build an initial set of synthetic data using numerical PDE solutions and then, using Deep Learning, devise a reduced model (in terms of computing because it is faster on its own or because it requires fewer variables).
REPSOL's interest in their capacities to tackle real issues was piqued by recent articles that addressed the problem of solving chaotic PDEs using Deep Learning approaches. In fact, the 139th ESGI group's Problem 3 aims to answer two preliminary issues about the application of Deep Learning to solve PDEs.
● What are the most relevant/optimal modes that reproduce the dynamics with a certain accuracy?
● Is numerical methods, and in particular, PDEs, the most effective way to model, solve, and predict dynamics?
Key takeaway
Nonlinearity must be taken into account while examining and assessing the status of dynamical systems. Previously computationally infeasible investigations are now easily executable on standard computer hardware thanks to recent improvements in computation.
Classification of objects is a relatively simple activity for humans, but it has proven to be a difficult challenge for machines, hence image classification has become a crucial task in the field of computer vision.
The categorising of images into one of a number of predefined classifications is referred to as image classification.
A given image can be categorised into an infinite number of different classes. Manually inspecting and classifying photographs can be time-consuming, especially when there are a large number of them (say 10,000), therefore it would be quite helpful if we could automate the entire process using computer vision.
Some examples of image classification include:
● Whether or not an x-ray is cancerous (binary classification).
● Classifying a digit written by hand (multiclass classification).
● Putting a name to a snapshot of a person's face (multiclass classification).
Structure of an Image Classification Task
● Image Preprocessing - The goal of this technique is to improve picture data (features) by suppressing undesired distortions and enhancing some key image aspects, so that our Computer Vision models can function with better data.
● Detection of an object - The term "detection" refers to the process of locating an object, which entails segmenting the image and determining the location of the object of interest.
● Feature extraction and Training- This is a critical stage in which statistical or deep learning approaches are used to discover the most intriguing patterns in the image, features that may be unique to a certain class and will later aid the model in distinguishing between them. Model training is the process through which the model learns the features from the dataset.
● Classification of the object - This stage uses an appropriate classification approach to classify observed objects into predetermined classes by comparing image patterns to target patterns.
Image Pre-processing
Pre-processing is a term used to describe operations on images at the most basic level of abstraction, where both the input and output are intensity images.
Need for Image-Preprocessing
Computers are capable of performing numerical computations but are unable to comprehend visuals in the same manner that humans do. We need to convert the photos to numbers so that the computer can understand them.
The goal of pre-processing is to improve the image data by suppressing unwanted distortions or enhancing certain visual qualities that are useful for subsequent processing.

Fig: How computers see an '8'
Steps for image pre-processing:
Step 1 - Reading Image
We just record the path to our image collection in a variable in this stage, and then create a method to load folders containing images into arrays so that computers can handle them.
Sample code for reading a two-class image dataset:
# importing libraries
From pathlib import Path
Import glob
Import pandas as pd
# reading images from path
Images_dir = Path('img')
Images = images_dir.glob("*.tif")
Train_data = []
Counter = 0
For img in images:
Counter += 1
If counter <= 130:
Train_data.append((img,1))
Else:
Train_data.append((img,0))
# converting data into pandas dataframe for easy visualization
Train_data = pd.DataFrame(train_data,columns=['image','label'],index = None)
Step 2 - Resize image
Because the size of some photos acquired by a camera and provided to our AI algorithm varies, we need resize all images fed to our AI algorithms to establish a base size.
The following is an example of code for scaling images to 229x229 dimensions:
Img = cv2.resize(img, (229,229))
Step 3 - Data Augmentation
Data augmentation is a technique for generating fresh 'data' with various orientations. This has two advantages: first, it allows you to generate more data' from limited data, and second, it inhibits overfitting.

Data Augmentation Techniques:
● Gray Scaling
The image will be transformed to grey scale (a range of grey hues ranging from white to black), and the computer will assign a value to each pixel based on its level of darkness. All of the numbers are gathered into an array, which is then used by the computer to perform calculations.
To convert an RGB(3 channels) image to a Gray scale image, use the following code:
Import cv2
Img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
● Reflection/Flip
Images can be flipped both horizontally and vertically. Vertical flips are not supported by all frameworks. A vertical flip, on the other hand, is the same as rotating an image 180 degrees and then flipping it horizontally.
Code
# horizontal flip
Img = cv2.flip(img, 0)
# vertical flip
Img = cv2.flip(img,1)

● Gaussian Blurring
The consequence of blurring an image with a Gaussian function is Gaussian blur (also known as Gaussian smoothing). It's a common effect in graphics software, and it's often used to minimise image noise.
Code
From scipy import ndimage
Img = ndimage.gaussian_filter(img, sigma= 5.11)
● Histogram Equalization
Another image processing technique that uses the image intensity histogram to boost global contrast in a picture is histogram equalisation. This method does not require any parameters, however it can occasionally produce an unnatural-looking image.
Code
Histogram equalization function
Def hist(img):
Img_to_yuv = cv2.cvtColor(img,cv2.COLOR_BGR2YUV)
Img_to_yuv[:,:,0] = cv2.equalizeHist(img_to_yuv[:,:,0])
Hist_equalization_result = cv2.cvtColor(img_to_yuv, cv2.COLOR_YUV2BGR)
Return hist_equalization_result
● Rotation
This is another another image enhancement method. It's possible that rotating an image won't keep its original dimensions (depending on what angle you choose to rotate it with )
Code
Import random
# function for rotation
Def rotation(img):
Rows,cols = img.shape[0],img.shape[1]
RandDeg = random.randint(-180, 180)
Matrix = cv2.getRotationMatrix2D((cols/2, rows/2), randDeg, 0.70)
Rotated = cv2.warpAffine(img, matrix, (rows, cols),
BorderMode=cv2.BORDER_CONSTANT,borderValue=(144, 159, 162))
Return rotated

As we progress from left to right, the photos are rotated 90 degrees clockwise in relation to the preceding one.
● Translation
The image is simply moved in the X or Y direction during translation (or both).
Because most things can be found practically everywhere in the image, this type of augmentation is extremely beneficial. As a result, our feature extractor is forced to search everywhere.
Code
Img = cv2.warpAffine(img, np.float32([[1, 0, 84], [0, 1, 56]]), (img.shape[0], img.shape[1]),
BorderMode=cv2.BORDER_CONSTANT,borderValue=(144, 159, 162))
Key takeaway
Classification of objects is a relatively simple activity for humans, but it has proven to be a difficult challenge for machines, hence image classification has become a crucial task in the field of computer vision.
Optimization is the problem of finding a set of inputs to an objective function that results in a maximum or minimum function evaluation.
It is the daunting issue that underlies many machine learning algorithms, from fitting logistic regression models to training artificial neural networks.
There are perhaps hundreds of popular optimization algorithms, and perhaps tens of algorithms to choose from in popular science code libraries. This can make it difficult to know which algorithms to consider for a given optimization problem.
In this, you can discover a guided tour of various optimization algorithms.
You will know about:
- Optimization algorithms may be grouped into those that use derivatives and those that do not.
- Classical algorithms use the first and often second derivative of the objective function.
- Direct search and stochastic algorithms are developed for objective functions where function derivatives are inaccessible.
Optimization Algorithm
Optimization refers to a method for finding the input parameters or arguments to a function that result in the minimum or maximum output of the function.
The most popular type of optimization problems encountered in machine learning are continuous function optimization, where the input arguments to the function are real-valued numeric values, e.g. Floating point values. The performance from the function is also a real-valued evaluation of the input values.
We might refer to problems of this form as continuous function optimization, to differentiate from functions that take discrete variables and are referred to as combinatorial optimization problems.
There are many different types of optimization algorithms that can be used for continuous function optimization problems, and maybe just as many ways to group and summaries them.
One approach to grouping optimization algorithms is based on the amount of knowledge available about the target function that is being optimised that, in turn, can be used and harnessed by the optimization algorithm.
Generally, the more information that is available about the target function, the simpler the function is to optimise if the information can easily be used in the search.
Perhaps the main division in optimization algorithms is whether the objective function can be distinguished at a point or not. That is, whether the first derivative (gradient or slope) of the function can be determined for a given candidate solution or not. This partitions algorithms into those that can make use of the measured gradient information and those that do not.
Key takeaway:
Optimization is the problem of finding a set of inputs to an objective function that results in a maximum or minimum function evaluation.
This is not an exhaustive coverage of algorithms for continuous function optimization, but it does cover the main approaches that you are likely to find as a frequent practitioner.
Scientists have created a material testing technique that improves on the accuracy of a previous technique used in production by utilising the power of machine learning.
The act of prodding a sample of a material with a sharp needle-like tip to see how the material responds by deforming is known as nano-indentation. Because of the technique's lack of precision in getting certain critical mechanical properties of a material, it hasn't been widely adopted in the manufacturing industry.
The new method is a hybrid that combines machine learning and nanoindentation techniques. It involves feeding empirically collected data to a neural network machine learning system utilising the usual nano-indentation procedure. The scientists then created and "trained" the system to be 20 times more accurate than previous methods in predicting sample yield strength.
The novel analytical technique, according to the researchers—a group from Nanyang Technological University, Singapore (NTU Singapore), Massachusetts Institute of Technology (MIT), and Brown University—can decrease the need for time-consuming and expensive computer simulations in part manufacturing. The method verifies that parts are safe to use in real-world situations and may be used in structural applications such as aeroplanes and vehicles, as well as parts created using digital manufacturing techniques like 3D printing.
"We have shown that combining the current breakthroughs in machine learning with nano-indentation can enhance the precision of material property predictions by up to 20 times," said NTU Distinguished University Professor Subra Suresh, the paper's senior corresponding author.
Suresh highlighted that the research validates the system's predictive capability and accuracy enhancement on traditionally manufactured aluminium alloys and 3D-printed titanium alloys, in addition to boosting the precision of material property estimations by up to 20 times. "This demonstrates the promise of our technology for digital manufacturing applications in Industry 4.0, particularly in areas like 3D printing," he said.
Hybrid approach
The procedure begins with a hard tip—typically constructed of a diamond-like substance—being pressed into the sample material at a regulated rate with precisely calibrated force, while continuously measuring the tip's penetration depth into the material being deformed.
To increase accuracy, the NTU, MIT, and Brown team created an advanced neural network—a computing system that is roughly modelled after the human brain—and "trained" it using a mix of real experimental data and computer-generated data. The researchers' "multi-fidelity" technique used deep learning algorithms to combine real experimental data with physics-based and computationally created "synthetic" data (from two-dimensional and three-dimensional computer simulations).
Previous attempts to apply machine learning to examine material qualities primarily relied on synthetic data generated by the computer under unrealistically perfect conditions, such as where the indenter tip form is perfectly sharp and the indenter motion is absolutely smooth. As a result, the measures predicted by machine learning were wrong.
However, it was shown that training the neural network with synthetic data first and then including a small number of real experimental data points improved the accuracy of the results.
When it comes to analysing the qualities of genuine materials, the researchers say that training with synthetic data can be done ahead of time, with a small number of real experimental results added for calibration.
Key takeaway
The act of prodding a sample of a material with a sharp needle-like tip to see how the material responds by deforming is known as nano-indentation. Because of the technique's lack of precision in getting certain critical mechanical properties of a material, it hasn't been widely adopted in the manufacturing industry.
For proportional plus-integral (PI) and proportional-plus-integral-plus-derivative (PID) control algorithms, controller timing relationships based on optimising the response of a first order lag plus dead time process are created. The feedback control loop's performance was measured using minimum error integrals. The proposed correlations are proved to have outstanding response qualities, especially for systems that need minimal or no overshoot.
The effect of applying the proportional action to the feedback variable in a PI control algorithm is investigated, and it is discovered that the proportional action provides a more consistent response to set point and load changes than the conventional PI algorithm, which is tuned for either set point or load changes.
A technique for adaptive gain adjustment is developed for a PI controller. The method is based on the identification of model parameters via sensitivity coefficient analysis. The chosen model is a second order lag, and the technique is used to control the temperature of a stirred tank chemical reactor. The proposed adaptive gain tuning technique outperformed the unadapted algorithm in terms of response time. The control systems analysed were simulated using digital computers.
In the literature, several various types of algorithms and tuning strategies for traditional analogue control and direct digital control of processes have been developed. The proportional, proportional plus integral, and proportional plus integral plus derivative are the most widely employed. These algorithms are popular because they are highly effective, linear, and simple to implement with analogue circuitry. With the introduction of the digital computer as a direct process controller, a number of previously untested control functions can be easily applied in the hopes of increasing the system's control performance. The impact of sample duration and the sensitivity to tuning parameters were also taken into account.
Control system
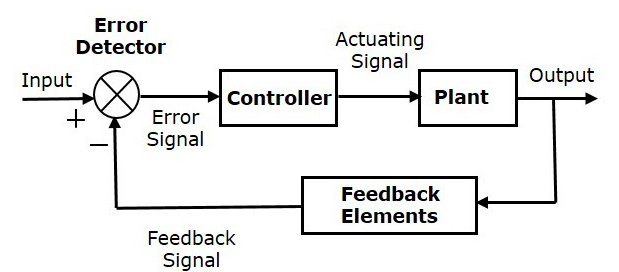
To put it another way, a control system takes a collection of inputs, regulates them to produce the intended output, and then directs them. There are two types of control systems:
1) Open-loop and
2) Closed-loop.
The main difference is that with closed-loop, the error is communicated as a feedback signal to the controller.
References:
- Deisenroth, Faisal, Ong, Mathematics for Machine Learning, Cambridge University Press, 2020.
- Stuart Russell and Peter Norvig (1995), “Artificial Intelligence: A Modern Approach,” Third edition, Pearson, 2003.
- Zsolt Nagy - Artificial Intelligence and Machine Learning Fundamentals-Apress (2018)
- Solanki, Kumar, Nayyar, Emerging Trends and Applications of Machine Learning, IGI Global, 2018.




