Unit - 2
Regular Grammars and Regular Expressions
If it has rules of form A -> an or A -> aB or A -> ⁇ where ⁇ is a special symbol called NULL, grammar is natural. Standard grammar is formal grammar, i.e. regular right or regular left. Regular language is defined in every periodic grammar
Right linear grammar
Right linear grammar is also called right regular grammar is a formal grammar N, Σ, P, S such that all the production rules in P are of one of the following forms:
- A → a, where A is a non-terminal in N and a is a terminal in Σ.
- A → aB, where A and B are non-terminals in N and a is in Σ
- A → ε, where A is in N and ε denotes the empty string, i.e. the string of length 0.
Left linear grammar
Left linear grammar is also called left regular grammar. There are some rules to follow:
- A → a, where A in N is a non-terminal and an in Σ is a terminal.
- A → Ba, where A and B in N are non-terminals and an in Σ is
- A → ε, where A is N and ε denotes the empty string, i.e. the longitudinal string 0.
Key takeaway
Right linear grammar, also called right regular grammar, is a formal grammar.
Left linear grammar is also called left regular grammar.
Conversion from regular grammar into FA
We are using the SubSet method to convert regular grammar into FA. Basically, this process is used to obtain FA from any given regular expression.
Some methods are as follows:
Step 1: Build a transition diagram, using NFA with ε moves, for a given regular expression.
Step 2: Transform this NFA to a non-ε NFA with ε.
Step 3: The received NFA is transformed to an analogous DFA.
Example:
Design the FA for regular expression 10 + (0 + 11)0* 1.
Sol: The first move is to construct the transition diagram for a given regular expression.
Step1:
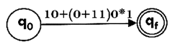
Step2:
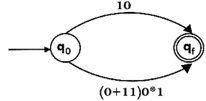
Step3:
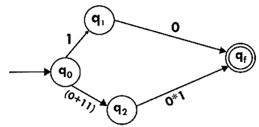
Step4:
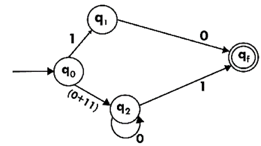
Step 5:
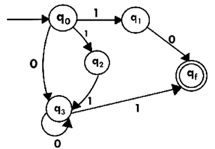
We've got an NFA now without ε. We're going to translate it into the necessary DFA for that now and we're going to write a transition table for this NFA first.
State | 0 | 1 |
→q0 | q3 | {q1,q2} |
q1 | Qf | ϕ |
q2 | ϕ | q3 |
q3 | q3 | Qf |
*qf | ϕ | ϕ |
The equivalent DFA transition table is:
State | 0 | 1 |
→[q0] | [q3] | [q1,q2] |
[q1] | [qf] | ϕ |
[q2] | ϕ | [q3] |
[q3] | [q3] | [qf] |
[q1,q2] | [qf] | [qf] |
*[qf] | ϕ | ϕ |
The fact that regular languages of any alphabet are countable, and we know that the set of all subsets of strings is not countable, ensures the existence of non-regular languages. Nonetheless, the purpose of developing non-regular languages is to demonstrate that some languages that are "computable" in some sense are not regular.
Example: This is the non-regular example we'd want to show:
L = { w ∈ {a,b}* : w = aibi, for some i ≥ 0 }
What is it about this language that makes it out of the ordinary? Consider the following string: w L. We'd have to keep track of how many a's we've seen and use that number to match off b's and accept if the numbers are equivalent. If we knew there were no more than 5 a's, we could use the following DFA (missing transitions lead to dead states):
The difficulty is that we only have a finite amount of memory, thus we will eventually run out of a's to remember. The goal is to pinpoint the finite memory constraint. The traditional Pumping Lemma is used to do this.
Theorem -
Let L be a regular language. Then a constant c' exists such that for every string w in L
|w| ≥ c
We are able to split w into three strings, w=xyz, so that
● |y| > 0
● |xy| ≤ c
● For all k ≥ 0, the string xyKz is also in L
Application of Pumping Lemma
It is important to apply Pumping Lemma to show that certain languages are not normal. It can never be used to illustrate the regularity of a language.
● If L is regular, it satisfies Pumping Lemma.
● If L does not satisfy Pumping Lemma, it is non-regular.
Method for demonstrating that a language L is not regular
● We have to assume that L is regular.
● The pumping lemma should hold for L.
● Use the pumping lemma to obtain a contradiction −
● Select w such that |w| ≥ c
● Select y such that |y| ≥ 1
● Select x such that |xy| ≤ c
● Assign the remaining string to z.
● Select k such that the resulting string is not in L.
Therefore, L is not regular.
Example:
Prove that L = {aibi | i ≥ 0} is not regular.
Sol:
● At first, we assume that L is regular and n is the number of states.
● Let w = anbn. Thus |w| = 2n ≥ n.
● By pumping lemma, let w = xyz, where |xy| ≤ n.
● Let x = ap , y = aq , and z = arbn , where p + q + r = n, p ≠ 0, q ≠ 0, r ≠ 0. Thus |y| ≠ 0.
● Let k = 2. Then xy2z = apa2qarbn.
● Number of as = (p + 2q + r) = (p + q + r) + q = n + q
● Hence, xy2z = an+q bn . Since q ≠ 0, xy2z is not of the form anbn .
● Thus, xy2z is not in L.
Hence L is not regular.
Regular languages are closed under a wide variety of operations.
Union and intersection -
Pick DFAs recognizing the two languages and use the cross-product construction to build a DFA recognizing their union or intersection.
Set complement -
Pick a DFA recognizing the language, then swap the accept/non-accept markings on its states.
Set difference -
Rewrite set difference using a combination of intersection and set complement
Concatenation and Star -
Pick an NFA recognizing the language and modify it
Homomorphism -
A homomorphism is a function from strings to strings. What makes it a homomorphism is that its output on a multi-character string is just the concatenation of its outputs on each individual character in the string. Or, equivalently, h(xy) = h(x)h(y) for any strings x and y. If S is a set of strings, then h(S) is {w : w = h(x) for some x in S}.
To show that regular languages are closed under homomorphism, choose an arbitrary regular language L and a homomorphism h. It can be represented using a regular expression R. But then h(R) is a regular expression representing h(L). So h(L) must also be regular.
Notice that regular languages are not closed under the subset/superset relation. For
Example, 0 * 1 * is regular, but its subset {O n 1 n : n >= 0} is not regular, but its subset {01,0011, 000111} is regular again.
● Simple expressions called Regular Expressions can readily define the language adopted by finite automata. This is the most powerful way of expressing any language.
● Regular languages are referred to as the languages recognised by certain regular expressions.
● A regular expression may also be defined as a pattern sequence that defines a series.
● For matching character combinations in strings, regular expressions are used. This pattern is used by the string search algorithm to locate operations on a string.
A Regular Expression can be recursively defined as follows −
● ε is a Regular Expression indicates the language containing an empty string. (L (ε) = {ε})
● φ is a Regular Expression denoting an empty language. (L (φ) = { })
● x is a Regular Expression where L = {x}
● If X is a Regular Expression denoting the language L(X) and Y is a Regular
● Expression denoting the language L(Y), then
● X + Y is a Regular Expression corresponding to the language L(X) ∪
L(Y) where L(X+Y) = L(X) ∪ L(Y).
● X . Y is a Regular Expression corresponding to the language L(X) .
L(Y) where L(X.Y) = L(X) . L(Y)
● R* is a Regular Expression corresponding to the language L(R*)
Where L(R*) = (L(R))*
● If we apply any of the rules several times from 1 to 5, they are Regular
Expressions.
Unix Operator Extensions
Regular expressions are used frequently in Unix:
● In the command line
● Within text editors
● In the context of pattern matching programs such as grep and egrep
Additional operators are recognized by unix. These operators are used for convenience only.
● character classes: ‘[‘ <list of chars> ‘]’
● start of a line: ‘^’
● end of a line: ‘$’
● wildcard matching any character except newline: ‘.’
● optional instance: R? = epsilon | R
● one or more instances: R+ == RR*
Key takeaway:
Regular languages are referred to as the languages recognised by certain regular expressions.
A regular expression may also be defined as a pattern sequence that defines a series.
- L + M = M + L
- (L + M) + N = L + (M + N)
- (LM)N = L(MN)
- ∅ + L = L + ∅ = L
- L = L = L
- ∅L = L∅ = ∅
- L(M + N) = LM + LN
- (M + N)L = ML + NL
- L + L = L
- (L ∗ ) ∗ = L ∗
- ∅ ∗ =
- ∗ =
- (xy) ∗x = x(yx) ∗
- The following are all equivalent:
(a) (x + y) ∗
(b) (x ∗ + y) ∗
(c) x ∗ (x + y) ∗
(d) (x + yx∗ ) ∗
(e) (x ∗ y ∗ ) ∗
(f) x ∗ (yx∗ ) ∗
(g) (x ∗ y) ∗x ∗
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
For every FA, there is a corresponding regular expression that generates the set of strings accepted by A.
The proof is in two parts:
1. An algorithm that, given a regular expression R, produces an FA A such that L(A) == L(R).
2. An algorithm that, given an FA A, produces a regular expression R such that L(R) == L(A).
Our construction of FA from regular expressions will allow “epsilon transitions” (a transition from one state to another with epsilon as the label). Such a transition is always possible, since epsilon (or the empty string) can be said to exist between any two input symbols.
We can show that such epsilon transitions are a notational convenience; for every FA with epsilon transitions there is a corresponding FA without them.
Constructing an FA from an RE
We begin by showing how to construct an FA for the operands in a regular expression.
If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
If the operand is epsilon, then our FA has two states, s0 (the start state) and Sf (the final, accepting state), and an epsilon transition from s0 to sF.
If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and R1*.
Let A (with start state a0 and final state aF) be the machine accepting L(R1) and B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Key takeaway
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
One method for converting a DFA to an equivalent RE is to replace states and transitions in the DFA graph with transitions tagged with the corresponding regular expressions one by one. Every transition in the DFA is de facto labeled with a regular expression at first. If there are many final states, a new final state with a -transition from each prior final state should be generated.
Consider the following FA, for instance, with three states.

A transformation labeled with the regular expression ab representing the concatenation of a and b can be substituted for state q1.

Next, with two states and two parallel transitions, consider the following FA.

A single transition labeled with the regular expression a+b representing the union of a and b will replace the two transitions.
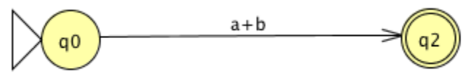
Now, consider the following FA, which involves a move to and from the same state.
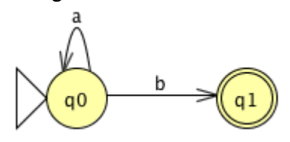
The Kleene star over a, which can be defined by the standard expression a*, indicates the transition. The two transitions can therefore be replaced by a single transition labeled with the standard expression a*b indicating that a* is concatenated with b.
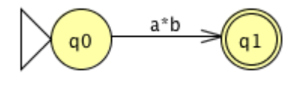
The mark on that transition is the regular expression equivalent to the original DFA once the FA graph has been decreased to two states (an initial state and a final state) and a single transition.
Key takeaway:
It has a finite number of states, the machine is called Deterministic Finite Machine or Deterministic Finite Automaton.
Any transformation in the DFA is initially de facto labeled with a periodic expression.
Regular expressions and finite automata have equivalent expressive power:
● For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
● For every FA , A there is a corresponding regular expression that generates the set of strings accepted by A.
The proof is in two parts:
1. An algorithm that, given a regular expression R, produces an FA A such that
L(A) == L(R).
2. An algorithm that, given an FA A, produces a regular expression R such that
L(R) == L(A).
Our construction of FA from regular expressions will allow “ epsilon transitions ” (a transition from one state to another with epsilon as the label). Such a transition is always possible, since epsilon (or the empty string) can be said to exist between any two input symbols. We can show that such epsilon transitions are a notational convenience; for every FA with epsilon transitions there is a corresponding FA without them.
Constructing an FA from an RE
We begin by showing how to construct an FA for the operands in a regular Expression.
● If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
● If the operand is epsilon, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and an epsilon transition from s0 to sF.
● If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and
R1*. Let A (with start state a0 and final state aF) be the machine accepting L(R1) and B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Key takeaway
Our construction of FA from regular expressions will allow “epsilon transitions” (a transition from one state to another with epsilon as the label).
Regular expressions are useful for a wide range of text processing jobs, as well as string processing in general, when the data isn't necessarily textual. Data validation, data scraping (particularly online scraping), data wrangling, simple parsing, the creation of syntax highlighting systems, and a variety of other activities are all common applications.
Reg exps are useful on Internet search engines, but depending on the complexity and design of the regex, processing them over the entire database could use a lot of computer resources.
References:
- Harry R. Lewis and Christos H. Papadimitriou, Elements of the Theory of Computation, Pearson Education Asia.
- Dexter C. Kozen, Automata and Computability, Undergraduate Texts in Computer Science, Springer.
- Michael Sipser, Introduction to the Theory of Computation, PWS Publishing.
- John Martin, “Introduction to Languages and The Theory of Computation”, 2nd Edition, McGraw Hill Education, ISBN-13: 978-1-25-900558-9, ISBN-10: 1-25-900558-5
- J.Carroll & D Long, “Theory of Finite Automata”, Prentice Hall, ISBN 0-13-913708-45
Unit - 2
Regular Grammars and Regular Expressions
If it has rules of form A -> an or A -> aB or A -> ⁇ where ⁇ is a special symbol called NULL, grammar is natural. Standard grammar is formal grammar, i.e. regular right or regular left. Regular language is defined in every periodic grammar
Right linear grammar
Right linear grammar is also called right regular grammar is a formal grammar N, Σ, P, S such that all the production rules in P are of one of the following forms:
- A → a, where A is a non-terminal in N and a is a terminal in Σ.
- A → aB, where A and B are non-terminals in N and a is in Σ
- A → ε, where A is in N and ε denotes the empty string, i.e. the string of length 0.
Left linear grammar
Left linear grammar is also called left regular grammar. There are some rules to follow:
- A → a, where A in N is a non-terminal and an in Σ is a terminal.
- A → Ba, where A and B in N are non-terminals and an in Σ is
- A → ε, where A is N and ε denotes the empty string, i.e. the longitudinal string 0.
Key takeaway
Right linear grammar, also called right regular grammar, is a formal grammar.
Left linear grammar is also called left regular grammar.
Conversion from regular grammar into FA
We are using the SubSet method to convert regular grammar into FA. Basically, this process is used to obtain FA from any given regular expression.
Some methods are as follows:
Step 1: Build a transition diagram, using NFA with ε moves, for a given regular expression.
Step 2: Transform this NFA to a non-ε NFA with ε.
Step 3: The received NFA is transformed to an analogous DFA.
Example:
Design the FA for regular expression 10 + (0 + 11)0* 1.
Sol: The first move is to construct the transition diagram for a given regular expression.
Step1:
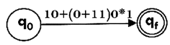
Step2:
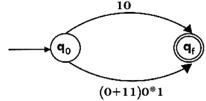
Step3:
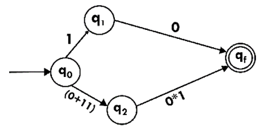
Step4:
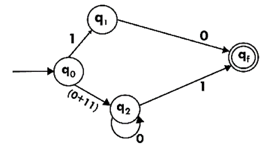
Step 5:
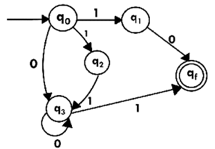
We've got an NFA now without ε. We're going to translate it into the necessary DFA for that now and we're going to write a transition table for this NFA first.
State | 0 | 1 |
→q0 | q3 | {q1,q2} |
q1 | Qf | ϕ |
q2 | ϕ | q3 |
q3 | q3 | Qf |
*qf | ϕ | ϕ |
The equivalent DFA transition table is:
State | 0 | 1 |
→[q0] | [q3] | [q1,q2] |
[q1] | [qf] | ϕ |
[q2] | ϕ | [q3] |
[q3] | [q3] | [qf] |
[q1,q2] | [qf] | [qf] |
*[qf] | ϕ | ϕ |
The fact that regular languages of any alphabet are countable, and we know that the set of all subsets of strings is not countable, ensures the existence of non-regular languages. Nonetheless, the purpose of developing non-regular languages is to demonstrate that some languages that are "computable" in some sense are not regular.
Example: This is the non-regular example we'd want to show:
L = { w ∈ {a,b}* : w = aibi, for some i ≥ 0 }
What is it about this language that makes it out of the ordinary? Consider the following string: w L. We'd have to keep track of how many a's we've seen and use that number to match off b's and accept if the numbers are equivalent. If we knew there were no more than 5 a's, we could use the following DFA (missing transitions lead to dead states):
The difficulty is that we only have a finite amount of memory, thus we will eventually run out of a's to remember. The goal is to pinpoint the finite memory constraint. The traditional Pumping Lemma is used to do this.
Theorem -
Let L be a regular language. Then a constant c' exists such that for every string w in L
|w| ≥ c
We are able to split w into three strings, w=xyz, so that
● |y| > 0
● |xy| ≤ c
● For all k ≥ 0, the string xyKz is also in L
Application of Pumping Lemma
It is important to apply Pumping Lemma to show that certain languages are not normal. It can never be used to illustrate the regularity of a language.
● If L is regular, it satisfies Pumping Lemma.
● If L does not satisfy Pumping Lemma, it is non-regular.
Method for demonstrating that a language L is not regular
● We have to assume that L is regular.
● The pumping lemma should hold for L.
● Use the pumping lemma to obtain a contradiction −
● Select w such that |w| ≥ c
● Select y such that |y| ≥ 1
● Select x such that |xy| ≤ c
● Assign the remaining string to z.
● Select k such that the resulting string is not in L.
Therefore, L is not regular.
Example:
Prove that L = {aibi | i ≥ 0} is not regular.
Sol:
● At first, we assume that L is regular and n is the number of states.
● Let w = anbn. Thus |w| = 2n ≥ n.
● By pumping lemma, let w = xyz, where |xy| ≤ n.
● Let x = ap , y = aq , and z = arbn , where p + q + r = n, p ≠ 0, q ≠ 0, r ≠ 0. Thus |y| ≠ 0.
● Let k = 2. Then xy2z = apa2qarbn.
● Number of as = (p + 2q + r) = (p + q + r) + q = n + q
● Hence, xy2z = an+q bn . Since q ≠ 0, xy2z is not of the form anbn .
● Thus, xy2z is not in L.
Hence L is not regular.
Regular languages are closed under a wide variety of operations.
Union and intersection -
Pick DFAs recognizing the two languages and use the cross-product construction to build a DFA recognizing their union or intersection.
Set complement -
Pick a DFA recognizing the language, then swap the accept/non-accept markings on its states.
Set difference -
Rewrite set difference using a combination of intersection and set complement
Concatenation and Star -
Pick an NFA recognizing the language and modify it
Homomorphism -
A homomorphism is a function from strings to strings. What makes it a homomorphism is that its output on a multi-character string is just the concatenation of its outputs on each individual character in the string. Or, equivalently, h(xy) = h(x)h(y) for any strings x and y. If S is a set of strings, then h(S) is {w : w = h(x) for some x in S}.
To show that regular languages are closed under homomorphism, choose an arbitrary regular language L and a homomorphism h. It can be represented using a regular expression R. But then h(R) is a regular expression representing h(L). So h(L) must also be regular.
Notice that regular languages are not closed under the subset/superset relation. For
Example, 0 * 1 * is regular, but its subset {O n 1 n : n >= 0} is not regular, but its subset {01,0011, 000111} is regular again.
● Simple expressions called Regular Expressions can readily define the language adopted by finite automata. This is the most powerful way of expressing any language.
● Regular languages are referred to as the languages recognised by certain regular expressions.
● A regular expression may also be defined as a pattern sequence that defines a series.
● For matching character combinations in strings, regular expressions are used. This pattern is used by the string search algorithm to locate operations on a string.
A Regular Expression can be recursively defined as follows −
● ε is a Regular Expression indicates the language containing an empty string. (L (ε) = {ε})
● φ is a Regular Expression denoting an empty language. (L (φ) = { })
● x is a Regular Expression where L = {x}
● If X is a Regular Expression denoting the language L(X) and Y is a Regular
● Expression denoting the language L(Y), then
● X + Y is a Regular Expression corresponding to the language L(X) ∪
L(Y) where L(X+Y) = L(X) ∪ L(Y).
● X . Y is a Regular Expression corresponding to the language L(X) .
L(Y) where L(X.Y) = L(X) . L(Y)
● R* is a Regular Expression corresponding to the language L(R*)
Where L(R*) = (L(R))*
● If we apply any of the rules several times from 1 to 5, they are Regular
Expressions.
Unix Operator Extensions
Regular expressions are used frequently in Unix:
● In the command line
● Within text editors
● In the context of pattern matching programs such as grep and egrep
Additional operators are recognized by unix. These operators are used for convenience only.
● character classes: ‘[‘ <list of chars> ‘]’
● start of a line: ‘^’
● end of a line: ‘$’
● wildcard matching any character except newline: ‘.’
● optional instance: R? = epsilon | R
● one or more instances: R+ == RR*
Key takeaway:
Regular languages are referred to as the languages recognised by certain regular expressions.
A regular expression may also be defined as a pattern sequence that defines a series.
- L + M = M + L
- (L + M) + N = L + (M + N)
- (LM)N = L(MN)
- ∅ + L = L + ∅ = L
- L = L = L
- ∅L = L∅ = ∅
- L(M + N) = LM + LN
- (M + N)L = ML + NL
- L + L = L
- (L ∗ ) ∗ = L ∗
- ∅ ∗ =
- ∗ =
- (xy) ∗x = x(yx) ∗
- The following are all equivalent:
(a) (x + y) ∗
(b) (x ∗ + y) ∗
(c) x ∗ (x + y) ∗
(d) (x + yx∗ ) ∗
(e) (x ∗ y ∗ ) ∗
(f) x ∗ (yx∗ ) ∗
(g) (x ∗ y) ∗x ∗
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
For every FA, there is a corresponding regular expression that generates the set of strings accepted by A.
The proof is in two parts:
1. An algorithm that, given a regular expression R, produces an FA A such that L(A) == L(R).
2. An algorithm that, given an FA A, produces a regular expression R such that L(R) == L(A).
Our construction of FA from regular expressions will allow “epsilon transitions” (a transition from one state to another with epsilon as the label). Such a transition is always possible, since epsilon (or the empty string) can be said to exist between any two input symbols.
We can show that such epsilon transitions are a notational convenience; for every FA with epsilon transitions there is a corresponding FA without them.
Constructing an FA from an RE
We begin by showing how to construct an FA for the operands in a regular expression.
If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
If the operand is epsilon, then our FA has two states, s0 (the start state) and Sf (the final, accepting state), and an epsilon transition from s0 to sF.
If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and R1*.
Let A (with start state a0 and final state aF) be the machine accepting L(R1) and B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Key takeaway
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
Unit - 2
Regular Grammars and Regular Expressions
If it has rules of form A -> an or A -> aB or A -> ⁇ where ⁇ is a special symbol called NULL, grammar is natural. Standard grammar is formal grammar, i.e. regular right or regular left. Regular language is defined in every periodic grammar
Right linear grammar
Right linear grammar is also called right regular grammar is a formal grammar N, Σ, P, S such that all the production rules in P are of one of the following forms:
- A → a, where A is a non-terminal in N and a is a terminal in Σ.
- A → aB, where A and B are non-terminals in N and a is in Σ
- A → ε, where A is in N and ε denotes the empty string, i.e. the string of length 0.
Left linear grammar
Left linear grammar is also called left regular grammar. There are some rules to follow:
- A → a, where A in N is a non-terminal and an in Σ is a terminal.
- A → Ba, where A and B in N are non-terminals and an in Σ is
- A → ε, where A is N and ε denotes the empty string, i.e. the longitudinal string 0.
Key takeaway
Right linear grammar, also called right regular grammar, is a formal grammar.
Left linear grammar is also called left regular grammar.
Conversion from regular grammar into FA
We are using the SubSet method to convert regular grammar into FA. Basically, this process is used to obtain FA from any given regular expression.
Some methods are as follows:
Step 1: Build a transition diagram, using NFA with ε moves, for a given regular expression.
Step 2: Transform this NFA to a non-ε NFA with ε.
Step 3: The received NFA is transformed to an analogous DFA.
Example:
Design the FA for regular expression 10 + (0 + 11)0* 1.
Sol: The first move is to construct the transition diagram for a given regular expression.
Step1:
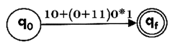
Step2:
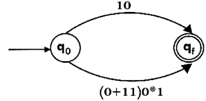
Step3:
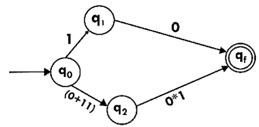
Step4:
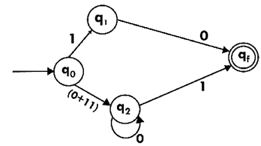
Step 5:
We've got an NFA now without ε. We're going to translate it into the necessary DFA for that now and we're going to write a transition table for this NFA first.
State | 0 | 1 |
→q0 | q3 | {q1,q2} |
q1 | Qf | ϕ |
q2 | ϕ | q3 |
q3 | q3 | Qf |
*qf | ϕ | ϕ |
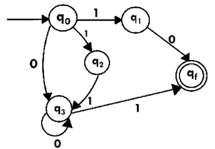
The equivalent DFA transition table is:
State | 0 | 1 |
→[q0] | [q3] | [q1,q2] |
[q1] | [qf] | ϕ |
[q2] | ϕ | [q3] |
[q3] | [q3] | [qf] |
[q1,q2] | [qf] | [qf] |
*[qf] | ϕ | ϕ |
The fact that regular languages of any alphabet are countable, and we know that the set of all subsets of strings is not countable, ensures the existence of non-regular languages. Nonetheless, the purpose of developing non-regular languages is to demonstrate that some languages that are "computable" in some sense are not regular.
Example: This is the non-regular example we'd want to show:
L = { w ∈ {a,b}* : w = aibi, for some i ≥ 0 }
What is it about this language that makes it out of the ordinary? Consider the following string: w L. We'd have to keep track of how many a's we've seen and use that number to match off b's and accept if the numbers are equivalent. If we knew there were no more than 5 a's, we could use the following DFA (missing transitions lead to dead states):
The difficulty is that we only have a finite amount of memory, thus we will eventually run out of a's to remember. The goal is to pinpoint the finite memory constraint. The traditional Pumping Lemma is used to do this.
Theorem -
Let L be a regular language. Then a constant c' exists such that for every string w in L
|w| ≥ c
We are able to split w into three strings, w=xyz, so that
● |y| > 0
● |xy| ≤ c
● For all k ≥ 0, the string xyKz is also in L
Application of Pumping Lemma
It is important to apply Pumping Lemma to show that certain languages are not normal. It can never be used to illustrate the regularity of a language.
● If L is regular, it satisfies Pumping Lemma.
● If L does not satisfy Pumping Lemma, it is non-regular.
Method for demonstrating that a language L is not regular
● We have to assume that L is regular.
● The pumping lemma should hold for L.
● Use the pumping lemma to obtain a contradiction −
● Select w such that |w| ≥ c
● Select y such that |y| ≥ 1
● Select x such that |xy| ≤ c
● Assign the remaining string to z.
● Select k such that the resulting string is not in L.
Therefore, L is not regular.
Example:
Prove that L = {aibi | i ≥ 0} is not regular.
Sol:
● At first, we assume that L is regular and n is the number of states.
● Let w = anbn. Thus |w| = 2n ≥ n.
● By pumping lemma, let w = xyz, where |xy| ≤ n.
● Let x = ap , y = aq , and z = arbn , where p + q + r = n, p ≠ 0, q ≠ 0, r ≠ 0. Thus |y| ≠ 0.
● Let k = 2. Then xy2z = apa2qarbn.
● Number of as = (p + 2q + r) = (p + q + r) + q = n + q
● Hence, xy2z = an+q bn . Since q ≠ 0, xy2z is not of the form anbn .
● Thus, xy2z is not in L.
Hence L is not regular.
Regular languages are closed under a wide variety of operations.
Union and intersection -
Pick DFAs recognizing the two languages and use the cross-product construction to build a DFA recognizing their union or intersection.
Set complement -
Pick a DFA recognizing the language, then swap the accept/non-accept markings on its states.
Set difference -
Rewrite set difference using a combination of intersection and set complement
Concatenation and Star -
Pick an NFA recognizing the language and modify it
Homomorphism -
A homomorphism is a function from strings to strings. What makes it a homomorphism is that its output on a multi-character string is just the concatenation of its outputs on each individual character in the string. Or, equivalently, h(xy) = h(x)h(y) for any strings x and y. If S is a set of strings, then h(S) is {w : w = h(x) for some x in S}.
To show that regular languages are closed under homomorphism, choose an arbitrary regular language L and a homomorphism h. It can be represented using a regular expression R. But then h(R) is a regular expression representing h(L). So h(L) must also be regular.
Notice that regular languages are not closed under the subset/superset relation. For
Example, 0 * 1 * is regular, but its subset {O n 1 n : n >= 0} is not regular, but its subset {01,0011, 000111} is regular again.
● Simple expressions called Regular Expressions can readily define the language adopted by finite automata. This is the most powerful way of expressing any language.
● Regular languages are referred to as the languages recognised by certain regular expressions.
● A regular expression may also be defined as a pattern sequence that defines a series.
● For matching character combinations in strings, regular expressions are used. This pattern is used by the string search algorithm to locate operations on a string.
A Regular Expression can be recursively defined as follows −
● ε is a Regular Expression indicates the language containing an empty string. (L (ε) = {ε})
● φ is a Regular Expression denoting an empty language. (L (φ) = { })
● x is a Regular Expression where L = {x}
● If X is a Regular Expression denoting the language L(X) and Y is a Regular
● Expression denoting the language L(Y), then
● X + Y is a Regular Expression corresponding to the language L(X) ∪
L(Y) where L(X+Y) = L(X) ∪ L(Y).
● X . Y is a Regular Expression corresponding to the language L(X) .
L(Y) where L(X.Y) = L(X) . L(Y)
● R* is a Regular Expression corresponding to the language L(R*)
Where L(R*) = (L(R))*
● If we apply any of the rules several times from 1 to 5, they are Regular
Expressions.
Unix Operator Extensions
Regular expressions are used frequently in Unix:
● In the command line
● Within text editors
● In the context of pattern matching programs such as grep and egrep
Additional operators are recognized by unix. These operators are used for convenience only.
● character classes: ‘[‘ <list of chars> ‘]’
● start of a line: ‘^’
● end of a line: ‘$’
● wildcard matching any character except newline: ‘.’
● optional instance: R? = epsilon | R
● one or more instances: R+ == RR*
Key takeaway:
Regular languages are referred to as the languages recognised by certain regular expressions.
A regular expression may also be defined as a pattern sequence that defines a series.
- L + M = M + L
- (L + M) + N = L + (M + N)
- (LM)N = L(MN)
- ∅ + L = L + ∅ = L
- L = L = L
- ∅L = L∅ = ∅
- L(M + N) = LM + LN
- (M + N)L = ML + NL
- L + L = L
- (L ∗ ) ∗ = L ∗
- ∅ ∗ =
- ∗ =
- (xy) ∗x = x(yx) ∗
- The following are all equivalent:
(a) (x + y) ∗
(b) (x ∗ + y) ∗
(c) x ∗ (x + y) ∗
(d) (x + yx∗ ) ∗
(e) (x ∗ y ∗ ) ∗
(f) x ∗ (yx∗ ) ∗
(g) (x ∗ y) ∗x ∗
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
For every FA, there is a corresponding regular expression that generates the set of strings accepted by A.
The proof is in two parts:
1. An algorithm that, given a regular expression R, produces an FA A such that L(A) == L(R).
2. An algorithm that, given an FA A, produces a regular expression R such that L(R) == L(A).
Our construction of FA from regular expressions will allow “epsilon transitions” (a transition from one state to another with epsilon as the label). Such a transition is always possible, since epsilon (or the empty string) can be said to exist between any two input symbols.
We can show that such epsilon transitions are a notational convenience; for every FA with epsilon transitions there is a corresponding FA without them.
Constructing an FA from an RE
We begin by showing how to construct an FA for the operands in a regular expression.
If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
If the operand is epsilon, then our FA has two states, s0 (the start state) and Sf (the final, accepting state), and an epsilon transition from s0 to sF.
If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and R1*.
Let A (with start state a0 and final state aF) be the machine accepting L(R1) and B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Key takeaway
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
One method for converting a DFA to an equivalent RE is to replace states and transitions in the DFA graph with transitions tagged with the corresponding regular expressions one by one. Every transition in the DFA is de facto labeled with a regular expression at first. If there are many final states, a new final state with a -transition from each prior final state should be generated.
Consider the following FA, for instance, with three states.

A transformation labeled with the regular expression ab representing the concatenation of a and b can be substituted for state q1.

Next, with two states and two parallel transitions, consider the following FA.

A single transition labeled with the regular expression a+b representing the union of a and b will replace the two transitions.
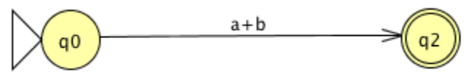
Now, consider the following FA, which involves a move to and from the same state.
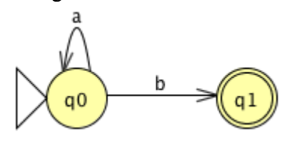
The Kleene star over a, which can be defined by the standard expression a*, indicates the transition. The two transitions can therefore be replaced by a single transition labeled with the standard expression a*b indicating that a* is concatenated with b.
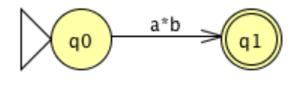
The mark on that transition is the regular expression equivalent to the original DFA once the FA graph has been decreased to two states (an initial state and a final state) and a single transition.
Key takeaway:
It has a finite number of states, the machine is called Deterministic Finite Machine or Deterministic Finite Automaton.
Any transformation in the DFA is initially de facto labeled with a periodic expression.
Regular expressions and finite automata have equivalent expressive power:
● For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
● For every FA , A there is a corresponding regular expression that generates the set of strings accepted by A.
The proof is in two parts:
1. An algorithm that, given a regular expression R, produces an FA A such that
L(A) == L(R).
2. An algorithm that, given an FA A, produces a regular expression R such that
L(R) == L(A).
Our construction of FA from regular expressions will allow “ epsilon transitions ” (a transition from one state to another with epsilon as the label). Such a transition is always possible, since epsilon (or the empty string) can be said to exist between any two input symbols. We can show that such epsilon transitions are a notational convenience; for every FA with epsilon transitions there is a corresponding FA without them.
Constructing an FA from an RE
We begin by showing how to construct an FA for the operands in a regular Expression.
● If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
● If the operand is epsilon, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and an epsilon transition from s0 to sF.
● If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and
R1*. Let A (with start state a0 and final state aF) be the machine accepting L(R1) and B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Key takeaway
Our construction of FA from regular expressions will allow “epsilon transitions” (a transition from one state to another with epsilon as the label).
Regular expressions are useful for a wide range of text processing jobs, as well as string processing in general, when the data isn't necessarily textual. Data validation, data scraping (particularly online scraping), data wrangling, simple parsing, the creation of syntax highlighting systems, and a variety of other activities are all common applications.
Reg exps are useful on Internet search engines, but depending on the complexity and design of the regex, processing them over the entire database could use a lot of computer resources.
References:
- Harry R. Lewis and Christos H. Papadimitriou, Elements of the Theory of Computation, Pearson Education Asia.
- Dexter C. Kozen, Automata and Computability, Undergraduate Texts in Computer Science, Springer.
- Michael Sipser, Introduction to the Theory of Computation, PWS Publishing.
- John Martin, “Introduction to Languages and The Theory of Computation”, 2nd Edition, McGraw Hill Education, ISBN-13: 978-1-25-900558-9, ISBN-10: 1-25-900558-5
- J.Carroll & D Long, “Theory of Finite Automata”, Prentice Hall, ISBN 0-13-913708-45
Unit - 2
Regular Grammars and Regular Expressions
If it has rules of form A -> an or A -> aB or A -> ⁇ where ⁇ is a special symbol called NULL, grammar is natural. Standard grammar is formal grammar, i.e. regular right or regular left. Regular language is defined in every periodic grammar
Right linear grammar
Right linear grammar is also called right regular grammar is a formal grammar N, Σ, P, S such that all the production rules in P are of one of the following forms:
- A → a, where A is a non-terminal in N and a is a terminal in Σ.
- A → aB, where A and B are non-terminals in N and a is in Σ
- A → ε, where A is in N and ε denotes the empty string, i.e. the string of length 0.
Left linear grammar
Left linear grammar is also called left regular grammar. There are some rules to follow:
- A → a, where A in N is a non-terminal and an in Σ is a terminal.
- A → Ba, where A and B in N are non-terminals and an in Σ is
- A → ε, where A is N and ε denotes the empty string, i.e. the longitudinal string 0.
Key takeaway
Right linear grammar, also called right regular grammar, is a formal grammar.
Left linear grammar is also called left regular grammar.
Conversion from regular grammar into FA
We are using the SubSet method to convert regular grammar into FA. Basically, this process is used to obtain FA from any given regular expression.
Some methods are as follows:
Step 1: Build a transition diagram, using NFA with ε moves, for a given regular expression.
Step 2: Transform this NFA to a non-ε NFA with ε.
Step 3: The received NFA is transformed to an analogous DFA.
Example:
Design the FA for regular expression 10 + (0 + 11)0* 1.
Sol: The first move is to construct the transition diagram for a given regular expression.
Step1:
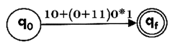
Step2:
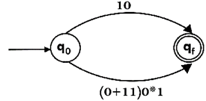
Step3:
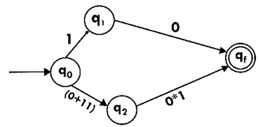
Step4:
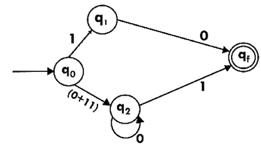
Step 5:
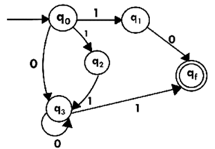
We've got an NFA now without ε. We're going to translate it into the necessary DFA for that now and we're going to write a transition table for this NFA first.
State | 0 | 1 |
→q0 | q3 | {q1,q2} |
q1 | Qf | ϕ |
q2 | ϕ | q3 |
q3 | q3 | Qf |
*qf | ϕ | ϕ |
The equivalent DFA transition table is:
State | 0 | 1 |
→[q0] | [q3] | [q1,q2] |
[q1] | [qf] | ϕ |
[q2] | ϕ | [q3] |
[q3] | [q3] | [qf] |
[q1,q2] | [qf] | [qf] |
*[qf] | ϕ | ϕ |
The fact that regular languages of any alphabet are countable, and we know that the set of all subsets of strings is not countable, ensures the existence of non-regular languages. Nonetheless, the purpose of developing non-regular languages is to demonstrate that some languages that are "computable" in some sense are not regular.
Example: This is the non-regular example we'd want to show:
L = { w ∈ {a,b}* : w = aibi, for some i ≥ 0 }
What is it about this language that makes it out of the ordinary? Consider the following string: w L. We'd have to keep track of how many a's we've seen and use that number to match off b's and accept if the numbers are equivalent. If we knew there were no more than 5 a's, we could use the following DFA (missing transitions lead to dead states):
The difficulty is that we only have a finite amount of memory, thus we will eventually run out of a's to remember. The goal is to pinpoint the finite memory constraint. The traditional Pumping Lemma is used to do this.
Theorem -
Let L be a regular language. Then a constant c' exists such that for every string w in L
|w| ≥ c
We are able to split w into three strings, w=xyz, so that
● |y| > 0
● |xy| ≤ c
● For all k ≥ 0, the string xyKz is also in L
Application of Pumping Lemma
It is important to apply Pumping Lemma to show that certain languages are not normal. It can never be used to illustrate the regularity of a language.
● If L is regular, it satisfies Pumping Lemma.
● If L does not satisfy Pumping Lemma, it is non-regular.
Method for demonstrating that a language L is not regular
● We have to assume that L is regular.
● The pumping lemma should hold for L.
● Use the pumping lemma to obtain a contradiction −
● Select w such that |w| ≥ c
● Select y such that |y| ≥ 1
● Select x such that |xy| ≤ c
● Assign the remaining string to z.
● Select k such that the resulting string is not in L.
Therefore, L is not regular.
Example:
Prove that L = {aibi | i ≥ 0} is not regular.
Sol:
● At first, we assume that L is regular and n is the number of states.
● Let w = anbn. Thus |w| = 2n ≥ n.
● By pumping lemma, let w = xyz, where |xy| ≤ n.
● Let x = ap , y = aq , and z = arbn , where p + q + r = n, p ≠ 0, q ≠ 0, r ≠ 0. Thus |y| ≠ 0.
● Let k = 2. Then xy2z = apa2qarbn.
● Number of as = (p + 2q + r) = (p + q + r) + q = n + q
● Hence, xy2z = an+q bn . Since q ≠ 0, xy2z is not of the form anbn .
● Thus, xy2z is not in L.
Hence L is not regular.
Regular languages are closed under a wide variety of operations.
Union and intersection -
Pick DFAs recognizing the two languages and use the cross-product construction to build a DFA recognizing their union or intersection.
Set complement -
Pick a DFA recognizing the language, then swap the accept/non-accept markings on its states.
Set difference -
Rewrite set difference using a combination of intersection and set complement
Concatenation and Star -
Pick an NFA recognizing the language and modify it
Homomorphism -
A homomorphism is a function from strings to strings. What makes it a homomorphism is that its output on a multi-character string is just the concatenation of its outputs on each individual character in the string. Or, equivalently, h(xy) = h(x)h(y) for any strings x and y. If S is a set of strings, then h(S) is {w : w = h(x) for some x in S}.
To show that regular languages are closed under homomorphism, choose an arbitrary regular language L and a homomorphism h. It can be represented using a regular expression R. But then h(R) is a regular expression representing h(L). So h(L) must also be regular.
Notice that regular languages are not closed under the subset/superset relation. For
Example, 0 * 1 * is regular, but its subset {O n 1 n : n >= 0} is not regular, but its subset {01,0011, 000111} is regular again.
● Simple expressions called Regular Expressions can readily define the language adopted by finite automata. This is the most powerful way of expressing any language.
● Regular languages are referred to as the languages recognised by certain regular expressions.
● A regular expression may also be defined as a pattern sequence that defines a series.
● For matching character combinations in strings, regular expressions are used. This pattern is used by the string search algorithm to locate operations on a string.
A Regular Expression can be recursively defined as follows −
● ε is a Regular Expression indicates the language containing an empty string. (L (ε) = {ε})
● φ is a Regular Expression denoting an empty language. (L (φ) = { })
● x is a Regular Expression where L = {x}
● If X is a Regular Expression denoting the language L(X) and Y is a Regular
● Expression denoting the language L(Y), then
● X + Y is a Regular Expression corresponding to the language L(X) ∪
L(Y) where L(X+Y) = L(X) ∪ L(Y).
● X . Y is a Regular Expression corresponding to the language L(X) .
L(Y) where L(X.Y) = L(X) . L(Y)
● R* is a Regular Expression corresponding to the language L(R*)
Where L(R*) = (L(R))*
● If we apply any of the rules several times from 1 to 5, they are Regular
Expressions.
Unix Operator Extensions
Regular expressions are used frequently in Unix:
● In the command line
● Within text editors
● In the context of pattern matching programs such as grep and egrep
Additional operators are recognized by unix. These operators are used for convenience only.
● character classes: ‘[‘ <list of chars> ‘]’
● start of a line: ‘^’
● end of a line: ‘$’
● wildcard matching any character except newline: ‘.’
● optional instance: R? = epsilon | R
● one or more instances: R+ == RR*
Key takeaway:
Regular languages are referred to as the languages recognised by certain regular expressions.
A regular expression may also be defined as a pattern sequence that defines a series.
- L + M = M + L
- (L + M) + N = L + (M + N)
- (LM)N = L(MN)
- ∅ + L = L + ∅ = L
- L = L = L
- ∅L = L∅ = ∅
- L(M + N) = LM + LN
- (M + N)L = ML + NL
- L + L = L
- (L ∗ ) ∗ = L ∗
- ∅ ∗ =
- ∗ =
- (xy) ∗x = x(yx) ∗
- The following are all equivalent:
(a) (x + y) ∗
(b) (x ∗ + y) ∗
(c) x ∗ (x + y) ∗
(d) (x + yx∗ ) ∗
(e) (x ∗ y ∗ ) ∗
(f) x ∗ (yx∗ ) ∗
(g) (x ∗ y) ∗x ∗
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
For every FA, there is a corresponding regular expression that generates the set of strings accepted by A.
The proof is in two parts:
1. An algorithm that, given a regular expression R, produces an FA A such that L(A) == L(R).
2. An algorithm that, given an FA A, produces a regular expression R such that L(R) == L(A).
Our construction of FA from regular expressions will allow “epsilon transitions” (a transition from one state to another with epsilon as the label). Such a transition is always possible, since epsilon (or the empty string) can be said to exist between any two input symbols.
We can show that such epsilon transitions are a notational convenience; for every FA with epsilon transitions there is a corresponding FA without them.
Constructing an FA from an RE
We begin by showing how to construct an FA for the operands in a regular expression.
If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
If the operand is epsilon, then our FA has two states, s0 (the start state) and Sf (the final, accepting state), and an epsilon transition from s0 to sF.
If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and R1*.
Let A (with start state a0 and final state aF) be the machine accepting L(R1) and B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Key takeaway
Regular expressions and finite automata have equivalent expressive power:
For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
One method for converting a DFA to an equivalent RE is to replace states and transitions in the DFA graph with transitions tagged with the corresponding regular expressions one by one. Every transition in the DFA is de facto labeled with a regular expression at first. If there are many final states, a new final state with a -transition from each prior final state should be generated.
Consider the following FA, for instance, with three states.

A transformation labeled with the regular expression ab representing the concatenation of a and b can be substituted for state q1.

Next, with two states and two parallel transitions, consider the following FA.

A single transition labeled with the regular expression a+b representing the union of a and b will replace the two transitions.
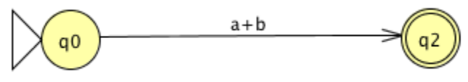
Now, consider the following FA, which involves a move to and from the same state.
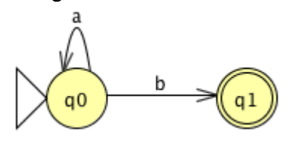
The Kleene star over a, which can be defined by the standard expression a*, indicates the transition. The two transitions can therefore be replaced by a single transition labeled with the standard expression a*b indicating that a* is concatenated with b.
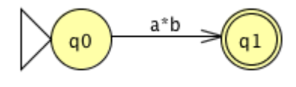
The mark on that transition is the regular expression equivalent to the original DFA once the FA graph has been decreased to two states (an initial state and a final state) and a single transition.
Key takeaway:
It has a finite number of states, the machine is called Deterministic Finite Machine or Deterministic Finite Automaton.
Any transformation in the DFA is initially de facto labeled with a periodic expression.
Regular expressions and finite automata have equivalent expressive power:
● For every regular expression R, there is a corresponding FA that accepts the set of strings generated by R.
● For every FA , A there is a corresponding regular expression that generates the set of strings accepted by A.
The proof is in two parts:
1. An algorithm that, given a regular expression R, produces an FA A such that
L(A) == L(R).
2. An algorithm that, given an FA A, produces a regular expression R such that
L(R) == L(A).
Our construction of FA from regular expressions will allow “ epsilon transitions ” (a transition from one state to another with epsilon as the label). Such a transition is always possible, since epsilon (or the empty string) can be said to exist between any two input symbols. We can show that such epsilon transitions are a notational convenience; for every FA with epsilon transitions there is a corresponding FA without them.
Constructing an FA from an RE
We begin by showing how to construct an FA for the operands in a regular Expression.
● If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
● If the operand is epsilon, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and an epsilon transition from s0 to sF.
● If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and
R1*. Let A (with start state a0 and final state aF) be the machine accepting L(R1) and B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Key takeaway
Our construction of FA from regular expressions will allow “epsilon transitions” (a transition from one state to another with epsilon as the label).
Regular expressions are useful for a wide range of text processing jobs, as well as string processing in general, when the data isn't necessarily textual. Data validation, data scraping (particularly online scraping), data wrangling, simple parsing, the creation of syntax highlighting systems, and a variety of other activities are all common applications.
Reg exps are useful on Internet search engines, but depending on the complexity and design of the regex, processing them over the entire database could use a lot of computer resources.
References:
- Harry R. Lewis and Christos H. Papadimitriou, Elements of the Theory of Computation, Pearson Education Asia.
- Dexter C. Kozen, Automata and Computability, Undergraduate Texts in Computer Science, Springer.
- Michael Sipser, Introduction to the Theory of Computation, PWS Publishing.
- John Martin, “Introduction to Languages and The Theory of Computation”, 2nd Edition, McGraw Hill Education, ISBN-13: 978-1-25-900558-9, ISBN-10: 1-25-900558-5
- J.Carroll & D Long, “Theory of Finite Automata”, Prentice Hall, ISBN 0-13-913708-45




