UNIT 3
Evaluating Hypotheses
This is made clear by distinguishing between the true error of a model and the estimated or sample error. One is the error rate of the hypothesis over the sample of data that is available. The other is the error rate of the hypothesis over the entire unknown distribution D of examples.
Machine learning, specifically supervised learning, can be described as the desire to use available data to learn a function that best maps inputs to outputs.
Technically, this is a problem called function approximation, where we are approximating an unknown target function (that we assume exists) that can best map inputs to outputs on all possible observations from the problem domain.
An example of a model that approximates the target function and performs mappings of inputs to outputs is called a hypothesis in machine learning.
The choice of algorithm (e.g. neural network) and the configuration of the algorithm (e.g. network topology and hyper parameters) define the space of possible hypotheses that the model may represent.
Learning for a machine learning algorithm involves navigating the chosen space of hypothesis toward the best or a good enough hypothesis that best approximates the target function.
This framing of machine learning is common and helps to understand the choice of algorithm, the problem of learning and generalization, and even the bias-variance trade-off. For example, the training dataset is used to learn a hypothesis and the test dataset is used to evaluate it.
A common notation is used where lowercase-h (h) represents a given specific hypothesis and uppercase-h (H) represents the hypothesis space that is being searched.
h (hypothesis): A single hypothesis, e.g. an instance or specific candidate model that maps inputs to outputs and can be evaluated and used to make predictions.
H (hypothesis set): A space of possible hypotheses for mapping inputs to outputs that can be searched, often constrained by the choice of the framing of the problem, the choice of model, and the choice of model configuration.
3.1.1 Basics of Sampling Theory
In the world of Statistics, the very first thing to be done before any estimation is to create a Sample set from the entire Population Set. The Population set can be seen as the entire tree from where data is collected whereas the Sample Set can be seen as the branch in which the actual study of observations and estimation is done. Population tree is a very large set and making the study of observations on it can be very exhausting, both time and money-wise alike. Thus to cut down on the amount of time and as well as resources, a Sample Set is created from the Population set.
Sampling Frame
The Sampling Frame is the basis of the sample medium. It is a collection of all the sample elements taken into observation. Sometimes it might even happen that all elements in the sampling frame, didn’t even take part in the actual statistics. In that case, the elements that took part in the study are called Samples and potential elements that could have been in the study but didn’t take part forms the Sampling Frame. Thus, Sampling Frame is the potential list of elements on which we will perform our statistics.
Coming up with a good sampling frame is very essential because it will help in predicting the reaction of the statistics results with the population set. A sampling frame is not just a random set of handpicked elements rather it even consists of identifiers that help to identify every element in the set.
Methods and Types of sampling:
3.1.2 Comparing Learning Algorithms
Difference between Supervised and Unsupervised Learning
Supervised and Unsupervised learning are the two techniques of machine learning. But both the techniques are used in different scenarios and with different datasets. Below the explanation of both learning methods along with their difference table is given.
Supervised Machine Learning:
Supervised learning is a machine learning method in which models are trained using labeled data. In supervised learning, models need to find the mapping function to map the input variable (X) with the output variable (Y).
Y= f( X)
Supervised learning needs supervision to train the model, which is similar to as a student learns things in the presence of a teacher. Supervised learning can be used for two types of problems: Classification and Regression.
Unsupervised Machine Learning:
Unsupervised learning is another machine learning method in which patterns are inferred from the unlabeled input data. The goal of unsupervised learning is to find the structure and patterns from the input data. Unsupervised learning does not need any supervision. Instead, it finds patterns from the data on its own.
Unsupervised learning can be used for two types of problems: Clustering and Association.
Example: To understand unsupervised learning, we will use the example given above. So unlike supervised learning, here we will not provide any supervision to the model. We will just provide the input dataset to the model and allow the model to find the patterns from the data. With the help of a suitable algorithm, the model will train itself and divide the fruits into different groups according to the most similar features between them.
The main differences between Supervised and Unsupervised learning are given below:
Unsupervised learning | |
supervised learning algorithms are trained using labeled data. | Unsupervised learning algorithms are trained using unlabeled data. |
A supervised learning model takes direct feedback to check if it is predicting the correct output or not. | The unsupervised learning model does not take any feedback |
The supervised learning model predicts the output | Unsupervised learning model finds the hidden patterns in data. |
In supervised learning, input data is provided to the model along with the output. | In unsupervised learning, only input data is provided to the model.
|
The goal of supervised learning is to train the model so that it can predict the output when it is given new data. | The goal of unsupervised learning is to find the hidden patterns and useful insights from the unknown dataset. |
Supervised learning needs supervision to train the model. | Unsupervised learning does not need any supervision to train the model. |
Supervised learning can be categorized into Classification and Regression problems | Unsupervised Learning can be classified in Clustering and Associations problems. |
Supervised learning can be used for those cases where we know the input as well as corresponding outputs. | Unsupervised learning can be used for those cases where we have only input data and no corresponding output data. |
A supervised learning model produces an accurate result. | An unsupervised learning model may give less accurate results as compared to supervised learning. |
KEY TAKEAWAYS
1. Simple Random Sampling
2. Systematic Sampling
3. Stratified Sampling
The Naïve Bayes algorithm is comprised of two words Naïve and Bayes, Which can be described as:
Naïve Bayes Classifier Algorithm
Naïve Bayes algorithm is a supervised learning algorithm, which is based on the Bayes theorem and used for solving classification problems. It is mainly used in text classification that includes a high-dimensional training dataset.
Naïve Bayes Classifier is one of the simple and most effective Classification algorithms which helps in building fast machine learning models that can make quick predictions.
It is a probabilistic classifier, which means it predicts based on the probability of an object.
Some popular examples of the Naïve Bayes Algorithm are spam filtration, Sentimental analysis, and classifying articles.

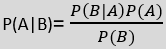
Where,
P(A|B) is Posterior probability: Probability of hypothesis A on the observed event B.
P(B|A) is Likelihood probability: Probability of the evidence given that the probability of a hypothesis is true.
P(A) is Prior Probability: Probability of hypothesis before observing the evidence.
P(B) is a Marginal Probability: Probability of Evidence.
3.2.1 Naïve Bayes classifier, Bayesian belief networks
Working of Naïve Bayes' Classifier:
Working of Naïve Bayes' Classifier can be understood with the help of the below example:
Suppose we have a dataset of weather conditions and corresponding target variable "Play". So using this dataset we need to decide whether we should play or not on a particular day according to the weather conditions. So to solve this problem, we need to follow the below steps:
Convert the given dataset into frequency tables.
Generate a Likelihood table by finding the probabilities of given features.
Now, use Bayes theorem to calculate the posterior probability.
Problem: If the weather is sunny, then the Player should play or not?
Solution: To solve this, first consider the below dataset:
Outlook Play
0 Rainy Yes
1 Sunny Yes
2 Overcast Yes
3 Overcast Yes
4 Sunny No
5 Rainy Yes
6 Sunny Yes
7 Overcast Yes
8 Rainy No
9 Sunny No
10 Sunny Yes
11 Rainy No
12 Overcast Yes
13 Overcast Yes
Frequency table for the Weather Conditions:
Weather Yes No
Overcast 5 0
Rainy 2 2
Sunny 3 2
Total 10 5
Likelihood table weather condition:
Weather No Yes
Overcast 0 5 5/14= 0.35
Rainy 2 2 4/14=0.29
Sunny 2 3 5/14=0.35
All 4/14=0.29 10/14=0.71
Applying Bayes'theorem:
P(Yes|Sunny)= P(Sunny|Yes)*P(Yes)/P(Sunny)
P(Sunny|Yes)= 3/10= 0.3
P(Sunny)= 0.35
P(Yes)=0.71
So P(Yes|Sunny) = 0.3*0.71/0.35= 0.60
P(No|Sunny)= P(Sunny|No)*P(No)/P(Sunny)
P(Sunny|NO)= 2/4=0.5
P(No)= 0.29
P(Sunny)= 0.35
So P(No|Sunny)= 0.5*0.29/0.35 = 0.41
So as we can see from the above calculation that P(Yes|Sunny)>P(No|Sunny)
Hence on a Sunny day, the Player can play the game.
Advantages of Naïve Bayes Classifier:
Naïve Bayes is one of the fast and easy ML algorithms to predict a class of datasets.
It can be used for Binary as well as Multi-class Classifications.
It performs well in Multi-class predictions as compared to the other Algorithms.
It is the most popular choice for text classification problems.
Disadvantages of Naïve Bayes Classifier:
Naive Bayes assumes that all features are independent or unrelated, so it cannot learn the relationship between features.
Applications of Naïve Bayes Classifier:
It is used for Credit Scoring.
It is used in medical data classification.
It can be used in real-time predictions because Naïve Bayes Classifier is an eager learner.
It is used in Text classification such as Spam filtering and Sentiment analysis.
Types of Naïve Bayes Model:
There are three types of Naive Bayes Model, which are given below:
Gaussian: The Gaussian model assumes that features follow a normal distribution. This means if predictors take continuous values instead of discrete, then the model assumes that these values are sampled from the Gaussian distribution.
Multinomial: The Multinomial Naïve Bayes classifier is used when the data is multinomial distributed. It is primarily used for document classification problems, it means a particular document belongs to which category such as Sports, Politics, education, etc.
The classifier uses the frequency of words for the predictors.
Bernoulli: The Bernoulli classifier works similarly to the Multinomial classifier, but the predictor variables are the independent Booleans variables. Such as if a particular word is present or not in a document. This model is also famous for document classification tasks.
In the real-world applications of machine learning, it is very common that there are many relevant features available for learning but only a small subset of them are observable. So, for the variables which are sometimes observable and sometimes not, then we can use the instances when that variable is visible is observed for learning and then predict its value in the instances when it is not observable.
On the other hand, the Expectation-Maximization algorithm can be used for the latent variables (variables that are not directly observable and are inferred from the values of the other observed variables) too to predict their values with the condition that the general form of probability distribution governing those latent variables is known to us. This algorithm is actually at the base of many unsupervised clustering algorithms in the field of machine learning.
It was explained, proposed, and given its name in a paper published in 1977 by Arthur Dempster, Nan Laird, and Donald Rubin. It is used to find the local maximum likelihood parameters of a statistical model in the cases where latent variables are involved and the data is missing or incomplete.
Algorithm:
Given a set of incomplete data, consider a set of starting parameters.
Expectation step (E – step): Using the observed available data of the dataset, estimate (guess) the values of the missing data.
Maximization step (M – step): Complete data generated after the expectation (E) step is used to update the parameters.
Repeat step 2 and step 3 until convergence
The essence of the Expectation-Maximization algorithm is to use the available observed data of the dataset to estimate the missing data and then using that data to update the values of the parameters. Let us understand the EM algorithm in detail.
Initially, a set of initial values of the parameters are considered. A set of incomplete observed data is given to the system with the assumption that the observed data comes from a specific model.
The next step is known as “Expectation” – step or E-step. In this step, we use the observed data to estimate or guess the values of the missing or incomplete data. It is used to update the variables.
The next step is known as “Maximization”-step or M-step. In this step, we use the complete data generated in the preceding “Expectation” – step to update the values of the parameters. It is used to update the hypothesis.
Now, in the fourth step, it is checked whether the values are converging or not, if yes, then stop otherwise repeat step-2 and step-3 i.e. “Expectation” – step and “Maximization” – step until the convergence occurs.
Usage of EM algorithm –
Advantages of EM algorithm –
Disadvantages of EM algorithm –
KEY TAKEAWAYS
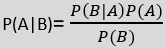
References:
1. Tom M. Mitchell, ―Machine Learning, McGraw-Hill Education (India) Private Limited, 2013.
2. Ethem Alpaydin, ―Introduction to Machine Learning (Adaptive Computation
And Machine Learning), The MIT Press 2004.
3. Stephen Marsland, ―Machine Learning: An Algorithmic Perspective, CRC Press, 2009.
4. Bishop, C., Pattern Recognition, and Machine Learning. Berlin: Springer-Verlag.




