UNIT 1
Introduction
A computer is a device that can accept human instruction processes it and responds to it or a computer is a computational device which is used to process the data under the control of a computer program. Program is a sequence of instruction along with data.
The basic components of a computer are:
- Input unit
- Central Processing Unit(CPU)
- Output unit
The CPU is further divided into three parts-
Memory unit
Control unit
Arithmetic Logic unit
Most of us have heard that CPU is called the brain of our computer because it accepts data, provides temporary memory space to it until it is stored(saved) on the hard disk, performs logical operations on it and hence processes (here also means converts) data into information. We all know that a computer consists of hardware and software. Software is a set of programs that performs multiple tasks together. An operating system is also a software (system software) that helps humans to interact with the computer system.
A program is a set of instructions given to a computer to perform a specific operation. Or computer is a computational device which is used to process the data under the control of a computer program. While executing the program, raw data is processed into a desired output format. These computer programs are written in a programming language which are high level languages. High level languages are nearly human languages which are more complex than the computer understandable language which are called machine language, or low-level language. So, after knowing the basics, we are ready to create a very simple and basic program. Like we have different languages to communicate with each other, likewise, we have different languages like C, C++, C#, Java, python, etc to communicate with the computers. The computer only understands binary language (the language of 0’s and 1’s) also called machine-understandable language or low-level language but the programs we are going to write are in a high-level language which is almost similar to human language.
The piece of code given below performs a basic task of printing “hello world! I am learning programming” on the console screen. We must know that keyboard, scanner, mouse, microphone, etc are various examples of input devices and monitor (console screen), printer, speaker, etc are the examples of output devices.
Main()
{
Clrscr();
Printf(“hello world! I am learning to program);
Getch();
}
At this stage, you might not be able to understand in-depth how this code prints something on the screen. The main() is a standard function that you will always include in any program that you are going to create from now onwards. Note that the execution of the program starts from the main() function. The clrscr() function is used to see only the current output on the screen while the printf () function helps us to print the desired output on the screen. Also, getch() is a function that accepts any character input from the keyboard. In simple words, we need to press any key to continue (some people may say that getch() helps in holding the screen to see the output).
Between high-level language and machine language there are assembly language also called symbolic machine code. Assembly language are particularly computer architecture specific. Utility program (Assembler) is used to convert assembly code into executable machine code. High Level Programming Language are portable but require Interpretation or compiling to convert it into a machine language which is computer understood.
Hierarchy of Computer language –

There have been many programming language some of them are listed below:
C | Python | C++ |
C# | R | Ruby |
COBOL | ADA | Java |
Fortran | BASIC | Altair BASIC |
True BASIC | Visual BASIC | GW BASIC |
QBASIC | PureBASIC | PASCAL |
Turbo Pascal | GO | ALGOL |
LISP | SCALA | Swift |
Rust | Prolog | Reia |
Racket | Scheme | Shimula |
Perl | PHP | Java Script |
CoffeeScript | VisualFoxPro | Babel |
Logo | Lua | Smalltalk |
Matlab | F | F# |
Dart | Datalog | Dbase |
Haskell | Dylan | Julia |
Ksh | Metro | Mumps |
Nim | OCaml | Pick |
TCL | D | CPL |
Curry | ActionScript | Erlang |
Clojure | DarkBASCIC | Assembly |
Most Popular Programming Languages –
- C
- Python
- C++
- Java
- SCALA
- C#
- R
- Ruby
- Go
- Swift
- JavaScript
Characteristics of a programming Language –
- A programming language must be simple, easy to learn and use, have good readability and human recognizable.
- Abstraction is a must-have Characteristics for a programming language in which ability to define the complex structure and then its degree of usability comes.
- A portable programming language is always preferred.
- Programming language’s efficiency must be high so that it can be easily converted into a machine code and executed consumes little space in memory.
- A programming language should be well structured and documented so that it is suitable for application development.
- Necessary tools for development, debugging, testing, maintenance of a program must be provided by a programming language.
- A programming language should provide single environment known as Integrated Development Environment (IDE).
- A programming language must be consistent in terms of syntax and semantics.
- 1.2 Introduction to components of a computer system (disks, memory, processor, where a program is stored and executed, operating system, compilers etc.)
Computer systems consist of three components as shown in below image: Central Processing Unit, Input devices and Output devices. Input devices provide data input to processor, which processes data and generates useful information that’s displayed to the user through output devices. This is stored in computer’s memory.
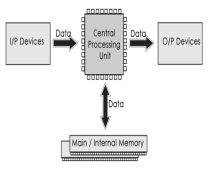
Central Processing Unit
The Central Processing Unit (CPU) is called "the brain of computer" as it controls operation of all parts of computer. It consists of two components: Arithmetic Logic Unit (ALU), and Control Unit.
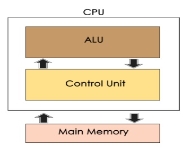
Arithmetic Logic Unit (ALU)
Data entered into computer is sent to RAM, from where it is then sent to ALU, where rest of data processing takes place. All types of processing, such as comparisons, decision-making and processing of non-numeric information takes place here and once again data is moved to RAM.
Control Unit
As name indicates, this part of CPU extracts instructions, performs execution, maintains and directs operations of entire system.
Functions of Control Unit
Control unit performs following functions −
- It controls all activities of computer
- Supervises flow of data within CPU
- Directs flow of data within CPU
- Transfers data to Arithmetic and Logic Unit
- Transfers results to memory
- Fetches results from memory to output devices
Memory Unit
This is unit in which data and instructions given to computer as well as results given by computer are stored. Unit of memory is "Byte".
1 Byte = 8 Bits
All types of computers follow the same basic logical structure and perform the following five basic operations for converting raw input data into information useful to their users.
S.No. | Operation | Description |
1 | Take Input | The process of entering data and instructions into the computer system. |
2 | Store Data | Saving data and instructions so that they are available for processing as and when required. |
3 | Processing Data | Performing arithmetic, and logical operations on data in order to convert them into useful information. |
4 | Output Information | The process of producing useful information or results for the user, such as a printed report or visual display. |
5 | Control the workflow | Directs the manner and sequence in which all of the above operations are performed. |
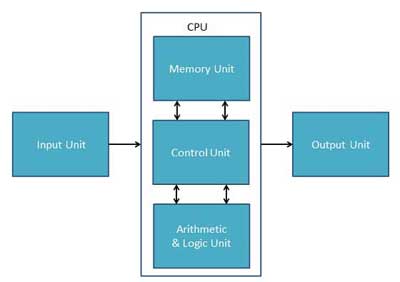
Input Unit
This unit contains devices with the help of which we enter data into the computer. This unit creates a link between the user and the computer. The input devices translate the information into a form understandable by the computer.
CPU (Central Processing Unit)
CPU is considered as the brain of the computer. CPU performs all types of data processing operations. It stores data, intermediate results, and instructions (program). It controls the operation of all parts of the computer.
CPU itself has the following three components −
- ALU (Arithmetic Logic Unit)
- Memory Unit
- Control Unit
Output Unit
The output unit consists of devices with the help of which we get the information from the computer. This unit is a link between the computer and the users. Output devices translate the computer's output into a form understandable by the users.
Input Devices
Following are some of the important input devices which are used in a computer −
- Keyboard
- Mouse
- Joy Stick
- Light pen
- Track Ball
- Scanner
- Graphic Tablet
- Microphone
- Magnetic Ink Card Reader(MICR)
- Optical Character Reader(OCR)
- Bar Code Reader
- Optical Mark Reader(OMR)
Keyboard
Keyboard is the most common and very popular input device which helps to input data to the computer. The layout of the keyboard is like that of traditional typewriter, although there are some additional keys provided for performing additional functions.

Keyboards are of two sizes 84 keys or 101/102 keys, but now keyboards with 104 keys or 108 keys are also available for Windows and Internet.
The keys on the keyboard are as follows −
S.No | Keys & Description |
1 | Typing Keys These keys include the letter keys (A-Z) and digit keys (09) which generally give the same layout as that of typewriters. |
2 | Numeric Keypad It is used to enter the numeric data or cursor movement. Generally, it consists of a set of 17 keys that are laid out in the same configuration used by most adding machines and calculators. |
3 | Function Keys The twelve function keys are present on the keyboard which are arranged in a row at the top of the keyboard. Each function key has a unique meaning and is used for some specific purpose. |
4 | Control keys These keys provide cursor and screen control. It includes four directional arrow keys. Control keys also include Home, End, Insert, Delete, Page Up, Page Down, Control(Ctrl), Alternate(Alt), Escape(Esc). |
5 | Special Purpose Keys Keyboard also contains some special purpose keys such as Enter, Shift, Caps Lock, Num Lock, Space bar, Tab, and Print Screen. |
Mouse
Mouse is the most popular pointing device. It is a very famous cursor-control device having a small palm size box with a round ball at its base, which senses the movement of the mouse and sends corresponding signals to the CPU when the mouse buttons are pressed.
Generally, it has two buttons called the left and the right button and a wheel is present between the buttons. A mouse can be used to control the position of the cursor on the screen, but it cannot be used to enter text into the computer.

Advantages
- Easy to use
- Not very expensive
- Moves the cursor faster than the arrow keys of the keyboard.
Joystick
Joystick is also a pointing device, which is used to move the cursor position on a monitor screen. It is a stick having a spherical ball at its both lower and upper ends. The lower spherical ball moves in a socket. The joystick can be moved in all four directions.

The function of the joystick is similar to that of a mouse. It is mainly used in Computer Aided Designing (CAD) and playing computer games.
Light Pen
Light pen is a pointing device similar to a pen. It is used to select a displayed menu item or draw pictures on the monitor screen. It consists of a photocell and an optical system placed in a small tube.

When the tip of a light pen is moved over the monitor screen and the pen button is pressed, its photocell sensing element detects the screen location and sends the corresponding signal to the CPU.
Track Ball
Track ball is an input device that is mostly used in notebook or laptop computer, instead of a mouse. This is a ball which is half inserted and by moving fingers on the ball, the pointer can be moved.

Since the whole device is not moved, a track ball requires less space than a mouse. A track ball comes in various shapes like a ball, a button, or a square.
Scanner
Scanner is an input device, which works more like a photocopy machine. It is used when some information is available on paper and it is to be transferred to the hard disk of the computer for further manipulation.

Scanner captures images from the source which are then converted into a digital form that can be stored on the disk. These images can be edited before they are printed.
Digitizer
Digitizer is an input device which converts analog information into digital form. Digitizer can convert a signal from the television or camera into a series of numbers that could be stored in a computer. They can be used by the computer to create a picture of whatever the camera had been pointed at.

Digitizer is also known as Tablet or Graphics Tablet as it converts graphics and pictorial data into binary inputs. A graphic tablet as digitizer is used for fine works of drawing and image manipulation applications.
Microphone
Microphone is an input device to input sound that is then stored in a digital form.

The microphone is used for various applications such as adding sound to a multimedia presentation or for mixing music.
Magnetic Ink Card Reader (MICR)
MICR input device is generally used in banks as there are large number of cheques to be processed every day. The bank's code number and cheque number are printed on the cheques with a special type of ink that contains particles of magnetic material that are machine readable.

This reading process is called Magnetic Ink Character Recognition (MICR). The main advantages of MICR is that it is fast and less error prone.
Optical Character Reader (OCR)
OCR is an input device used to read a printed text.

OCR scans the text optically, character by character, converts them into a machine readable code, and stores the text on the system memory.
Bar Code Readers
Bar Code Reader is a device used for reading bar coded data (data in the form of light and dark lines). Bar coded data is generally used in labelling goods, numbering the books, etc. It may be a handheld scanner or may be embedded in a stationary scanner.

Bar Code Reader scans a bar code image, converts it into an alphanumeric value, which is then fed to the computer that the bar code reader is connected to.
Optical Mark Reader (OMR)
OMR is a special type of optical scanner used to recognize the type of mark made by pen or pencil. It is used where one out of a few alternatives is to be selected and marked.

It is specially used for checking the answer sheets of examinations having multiple choice questions.
Output Devices
Following are some of the important output devices used in a computer.
- Monitors
- Graphic Plotter
- Printer
Monitors
Monitors, commonly called as Visual Display Unit (VDU), are the main output device of a computer. It forms images from tiny dots, called pixels that are arranged in a rectangular form. The sharpness of the image depends upon the number of pixels.
There are two kinds of viewing screen used for monitors.
- Cathode-Ray Tube (CRT)
- Flat-Panel Display
Cathode-Ray Tube (CRT) Monitor
The CRT display is made up of small picture elements called pixels. The smaller the pixels, the better the image clarity or resolution. It takes more than one illuminated pixel to form a whole character, such as the letter ‘e’ in the word help.

A finite number of characters can be displayed on a screen at once. The screen can be divided into a series of character boxes - fixed location on the screen where a standard character can be placed. Most screens are capable of displaying 80 characters of data horizontally and 25 lines vertically.
There are some disadvantages of CRT −
- Large in Size
- High power consumption
Flat-Panel Display Monitor
The flat-panel display refers to a class of video devices that have reduced volume, weight and power requirement in comparison to the CRT. You can hang them on walls or wear them on your wrists. Current uses of flat-panel displays include calculators, video games, monitors, laptop computer, and graphics display.

The flat-panel display is divided into two categories −
- Emissive Displays − Emissive displays are devices that convert electrical energy into light. For example, plasma panel and LED (Light-Emitting Diodes).
- Non-Emissive Displays − Non-emissive displays use optical effects to convert sunlight or light from some other source into graphics patterns. For example, LCD (Liquid-Crystal Device).
Printers
Printer is an output device, which is used to print information on paper.
There are two types of printers −
- Impact Printers
- Non-Impact Printers
Impact Printers
Impact printers print the characters by striking them on the ribbon, which is then pressed on the paper.
Characteristics of Impact Printers are the following −
- Very low consumable costs
- Very noisy
- Useful for bulk printing due to low cost
- There is physical contact with the paper to produce an image
These printers are of two types −
- Character printers
- Line printers
Character Printers
Character printers are the printers which print one character at a time.
These are further divided into two types:
- Dot Matrix Printer(DMP)
- Daisy Wheel
Dot Matrix Printer
In the market, one of the most popular printers is Dot Matrix Printer. These printers are popular because of their ease of printing and economical price. Each character printed is in the form of pattern of dots and head consists of a Matrix of Pins of size (5*7, 7*9, 9*7 or 9*9) which come out to form a character which is why it is called Dot Matrix Printer.

Advantages
- Inexpensive
- Widely Used
- Other language characters can be printed
Disadvantages
- Slow Speed
- Poor Quality
Daisy Wheel
Head is lying on a wheel and pins corresponding to characters are like petals of Daisy (flower) which is why it is called Daisy Wheel Printer. These printers are generally used for word-processing in offices that require a few letters to be sent here and there with very nice quality.

Advantages
- More reliable than DMP
- Better quality
- Fonts of character can be easily changed
Disadvantages
- Slower than DMP
- Noisy
- More expensive than DMP
Line Printers
Line printers are the printers which print one line at a time.

These are of two types −
- Drum Printer
- Chain Printer
Drum Printer
This printer is like a drum in shape hence it is called drum printer. The surface of the drum is divided into a number of tracks. Total tracks are equal to the size of the paper, i.e. for a paper width of 132 characters, drum will have 132 tracks. A character set is embossed on the track. Different character sets available in the market are 48 character set, 64 and 96 characters set. One rotation of drum prints one line. Drum printers are fast in speed and can print 300 to 2000 lines per minute.
Advantages
- Very high speed
Disadvantages
- Very expensive
- Characters fonts cannot be changed
Chain Printer
In this printer, a chain of character sets is used, hence it is called Chain Printer. A standard character set may have 48, 64, or 96 characters.
Advantages
- Character fonts can easily be changed.
- Different languages can be used with the same printer.
Disadvantages
- Noisy
Non-impact Printers
Non-impact printers print the characters without using the ribbon. These printers print a complete page at a time, thus they are also called as Page Printers.
These printers are of two types −
- Laser Printers
- Inkjet Printers
Characteristics of Non-impact Printers
- Faster than impact printers
- They are not noisy
- High quality
- Supports many fonts and different character size
Laser Printers
These are non-impact page printers. They use laser lights to produce the dots needed to form the characters to be printed on a page.

Advantages
- Very high speed
- Very high quality output
- Good graphics quality
- Supports many fonts and different character size
Disadvantages
- Expensive
- Cannot be used to produce multiple copies of a document in a single printing
Inkjet Printers
Inkjet printers are non-impact character printers based on a relatively new technology. They print characters by spraying small drops of ink onto paper. Inkjet printers produce high quality output with presentable features.

They make less noise because no hammering is done and these have many styles of printing modes available. Colour printing is also possible. Some models of Inkjet printers can produce multiple copies of printing also.
Advantages
- High quality printing
- More reliable
Disadvantages
- Expensive as the cost per page is high
- Slow as compared to laser printer
Memory
A memory is just like a human brain. It is used to store data and instructions. Computer memory is the storage space in the computer, where data is to be processed and instructions required for processing are stored. The memory is divided into large number of small parts called cells. Each location or cell has a unique address, which varies from zero to memory size minus one. For example, if the computer has 64k words, then this memory unit has 64 * 1024 = 65536 memory locations. The address of these locations varies from 0 to 65535.
Memory is primarily of three types −
- Cache Memory
- Primary Memory/Main Memory
- Secondary Memory
Cache Memory
Cache memory is a very high speed semiconductor memory which can speed up the CPU. It acts as a buffer between the CPU and the main memory. It is used to hold those parts of data and program which are most frequently used by the CPU. The parts of data and programs are transferred from the disk to cache memory by the operating system, from where the CPU can access them.

Advantages
The advantages of cache memory are as follows −
- Cache memory is faster than main memory.
- It consumes less access time as compared to main memory.
- It stores the program that can be executed within a short period of time.
- It stores data for temporary use.
Disadvantages
The disadvantages of cache memory are as follows −
- Cache memory has limited capacity.
- It is very expensive.
Primary Memory (Main Memory)
Primary memory holds only those data and instructions on which the computer is currently working. It has a limited capacity and data is lost when power is switched off. It is generally made up of semiconductor device. These memories are not as fast as registers. The data and instruction required to be processed resides in the main memory. It is divided into two subcategories RAM and ROM.

Characteristics of Main Memory
- These are semiconductor memories.
- It is known as the main memory.
- Usually volatile memory.
- Data is lost in case power is switched off.
- It is the working memory of the computer.
- Faster than secondary memories.
- A computer cannot run without the primary memory.
Secondary Memory
This type of memory is also known as external memory or non-volatile. It is slower than the main memory. These are used for storing data/information permanently. CPU directly does not access these memories, instead they are accessed via input-output routines. The contents of secondary memories are first transferred to the main memory, and then the CPU can access it. For example, disk, CD-ROM, DVD, etc.

Characteristics of Secondary Memory
- These are magnetic and optical memories.
- It is known as the backup memory.
- It is a non-volatile memory.
- Data is permanently stored even if power is switched off.
- It is used for storage of data in a computer.
- Computer may run without the secondary memory.
- Slower than primary memories.
Motherboard
The motherboard serves as a single platform to connect all of the parts of a computer together. It connects the CPU, memory, hard drives, optical drives, video card, sound card, and other ports and expansion cards directly or via cables. It can be considered as the backbone of a computer.

Features of Motherboard
A motherboard comes with following features −
- Motherboard varies greatly in supporting various types of components.
- Motherboard supports a single type of CPU and few types of memories.
- Video cards, hard disks, sound cards have to be compatible with the motherboard to function properly.
- Motherboards, cases, and power supplies must be compatible to work properly together.
Popular Manufacturers
Following are the popular manufacturers of the motherboard.
- Intel
- ASUS
- AOpen
- ABIT
- Biostar
- Gigabyte
- MSI
Description of Motherboard
The motherboard is mounted inside the case and is securely attached via small screws through pre-drilled holes. Motherboard contains ports to connect all of the internal components. It provides a single socket for CPU, whereas for memory, normally one or more slots are available. Motherboards provide ports to attach the floppy drive, hard drive, and optical drives via ribbon cables. Motherboard carries fans and a special port designed for power supply.
There is a peripheral card slot in front of the motherboard using which video cards, sound cards, and other expansion cards can be connected to the motherboard.
On the left side, motherboards carry a number of ports to connect the monitor, printer, mouse, keyboard, speaker, and network cables. Motherboards also provide USB ports, which allow compatible devices to be connected in plug-in/plug-out fashion. For example, pen drive, digital cameras, etc.
Memory Units
Memory unit is the amount of data that can be stored in the storage unit. This storage capacity is expressed in terms of Bytes.
The following table explains the main memory storage units −
S.No. | Unit & Description |
1 | Bit (Binary Digit) A binary digit is logical 0 and 1 representing a passive or an active state of a component in an electric circuit. |
2 | Nibble A group of 4 bits is called nibble. |
3 | Byte A group of 8 bits is called byte. A byte is the smallest unit, which can represent a data item or a character. |
4 | Word A computer word, like a byte, is a group of fixed number of bits processed as a unit, which varies from computer to computer but is fixed for each computer. The length of a computer word is called word-size or word length. It may be as small as 8 bits or may be as long as 96 bits. A computer stores the information in the form of computer words. |
The following table lists some higher storage units −
S.No. | Unit & Description |
1 | Kilobyte (KB) 1 KB = 1024 Bytes |
2 | Megabyte (MB) 1 MB = 1024 KB |
3 | GigaByte (GB) 1 GB = 1024 MB |
4 | TeraByte (TB) 1 TB = 1024 GB |
5 | PetaByte (PB) 1 PB = 1024 TB |
Random Access Memory
RAM (Random Access Memory) is the internal memory of the CPU for storing data, program, and program result. It is a read/write memory which stores data until the machine is working. As soon as the machine is switched off, data is erased.

Access time in RAM is independent of the address, that is, each storage location inside the memory is as easy to reach as other locations and takes the same amount of time. Data in the RAM can be accessed randomly but it is very expensive.
RAM is volatile, i.e. data stored in it is lost when we switch off the computer or if there is a power failure. Hence, a backup Uninterruptible Power System (UPS) is often used with computers. RAM is small, both in terms of its physical size and in the amount of data it can hold.
RAM is of two types −
- Static RAM (SRAM)
- Dynamic RAM (DRAM)
Static RAM (SRAM)
The word static indicates that the memory retains its contents as long as power is being supplied. However, data is lost when the power gets down due to volatile nature. SRAM chips use a matrix of 6-transistors and no capacitors. Transistors do not require power to prevent leakage, so SRAM need not be refreshed on a regular basis.
There is extra space in the matrix, hence SRAM uses more chips than DRAM for the same amount of storage space, making the manufacturing costs higher. SRAM is thus used as cache memory and has very fast access.
Characteristic of Static RAM
- Long life
- No need to refresh
- Faster
- Used as cache memory
- Large size
- Expensive
- High power consumption
Dynamic RAM (DRAM)
DRAM, unlike SRAM, must be continually refreshed in order to maintain the data. This is done by placing the memory on a refresh circuit that rewrites the data several hundred times per second. DRAM is used for most system memory as it is cheap and small. All DRAMs are made up of memory cells, which are composed of one capacitor and one transistor.
Characteristics of Dynamic RAM
- Short data lifetime
- Needs to be refreshed continuously
- Slower as compared to SRAM
- Used as RAM
- Smaller in size
- Less expensive
- Less power consumption
Read Only Memory
ROM stands for Read Only Memory. The memory from which we can only read but cannot write on it. This type of memory is non-volatile. The information is stored permanently in such memories during manufacture. A ROM stores such instructions that are required to start a computer. This operation is referred to as bootstrap. ROM chips are not only used in the computer but also in other electronic items like washing machine and microwave oven.

Let us now discuss the various types of ROMs and their characteristics.
MROM (Masked ROM)
The very first ROMs were hard-wired devices that contained a pre-programmed set of data or instructions. These kinds of ROMs are known as masked ROMs, which are inexpensive.
PROM (Programmable Read Only Memory)
PROM is read-only memory that can be modified only once by a user. The user buys a blank PROM and enters the desired contents using a PROM program. Inside the PROM chip, there are small fuses which are burnt open during programming. It can be programmed only once and is not erasable.
EPROM (Erasable and Programmable Read Only Memory)
EPROM can be erased by exposing it to ultra-violet light for a duration of up to 40 minutes. Usually, an EPROM eraser achieves this function. During programming, an electrical charge is trapped in an insulated gate region. The charge is retained for more than 10 years because the charge has no leakage path. For erasing this charge, ultra-violet light is passed through a quartz crystal window (lid). This exposure to ultra-violet light dissipates the charge. During normal use, the quartz lid is sealed with a sticker.
EEPROM (Electrically Erasable and Programmable Read Only Memory)
EEPROM is programmed and erased electrically. It can be erased and reprogrammed about ten thousand times. Both erasing and programming take about 4 to 10 ms (millisecond). In EEPROM, any location can be selectively erased and programmed. EEPROMs can be erased one byte at a time, rather than erasing the entire chip. Hence, the process of reprogramming is flexible but slow.
Advantages of ROM
The advantages of ROM are as follows −
- Non-volatile in nature
- Cannot be accidentally changed
- Cheaper than RAMs
- Easy to test
- More reliable than RAMs
- Static and do not require refreshing
- Contents are always known and can be verified
Algorithm
The word algorithm means “a process or set of rules to be followed in calculations or other problem-solving operations”. Therefore Algorithm refers to a set of rules/instructions that step-by-step define how a work is to be executed upon in order to get the expected results.
It can be understood by taking an example of cooking a new recipe. To cook a new recipe, one reads the instructions and steps and execute them one by one, in the given sequence. The result thus obtained is the new dish cooked perfectly. Similarly, algorithms help to do a task in programming to get the expected output.
The Algorithm designed are language-independent, i.e. they are just plain instructions that can be implemented in any language, and yet the output will be the same, as expected.
What are the Characteristics of an Algorithm?
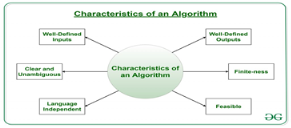
As one would not follow any written instructions to cook the recipe, but only the standard one. Similarly, not all written instructions for programming is an algorithm. In order for some instructions to be an algorithm, it must have the following characteristics:
- Clear and Unambiguous: Algorithm should be clear and unambiguous. Each of its steps should be clear in all aspects and must lead to only one meaning.
- Well-Defined Inputs: If an algorithm says to take inputs, it should be well-defined inputs.
- Well-Defined Outputs: The algorithm must clearly define what output will be yielded and it should be well-defined as well.
- Finite-ness: The algorithm must be finite, i.e. it should not end up in an infinite loops or similar.
- Feasible: The algorithm must be simple, generic and practical, such that it can be executed upon will the available resources. It must not contain some future technology, or anything.
- Language Independent: The Algorithm designed must be language-independent, i.e. it must be just plain instructions that can be implemented in any language, and yet the output will be same, as expected.
How to Design an Algorithm?
In order to write an algorithm, following things are needed as a pre-requisite:
- The problem that is to be solved by this algorithm.
- The constraints of the problem that must be considered while solving the problem.
- The input to be taken to solve the problem.
- The output to be expected when the problem the is solved.
- The solution to this problem, in the given constraints.
Then the algorithm is written with the help of above parameters such that it solves the problem.
Example: Consider the example to add three numbers and print the sum.
- Step 1: Fulfilling the pre-requisites
As discussed above, in order to write an algorithm, its pre-requisites must be fulfilled.
- The problem that is to be solved by this algorithm: Add 3 numbers and print their sum.
- The constraints of the problem that must be considered while solving the problem: The numbers must contain only digits and no other characters.
- The input to be taken to solve the problem: The three numbers to be added.
- The output to be expected when the problem the is solved: The sum of the three numbers taken as the input.
- The solution to this problem, in the given constraints: The solution consists of adding the 3 numbers. It can be done with the help of ‘+’ operator, or bit-wise, or any other method.
- Step 2: Designing the algorithm
Now let’s design the algorithm with the help of above pre-requisites:
Algorithm to add 3 numbers and print their sum:
- START
- Declare 3 integer variables num1, num2 and num3.
- Take the three numbers, to be added, as inputs in variables num1, num2, and num3 respectively.
- Declare an integer variable sum to store the resultant sum of the 3 numbers.
- Add the 3 numbers and store the result in the variable sum.
- Print the value of variable sum
- END
- Step 3: Testing the algorithm by implementing it.
In order to test the algorithm, let’s implement it in C language.
Program:
// C program to add three numbers // with the help of above designed algorithm
#include <stdio.h>
Int main() {
// Variables to take the input of the 3 numbers Int num1, num2, num3;
// Variable to store the resultant sum Int sum;
// Take the 3 numbers as input Printf("Enter the 1st number: "); Scanf("%d", &num1); Printf("%d\n", num1);
Printf("Enter the 2nd number: "); Scanf("%d", &num2); Printf("%d\n", num2);
Printf("Enter the 3rd number: "); Scanf("%d", &num3); Printf("%d\n", num3);
// Calculate the sum using + operator // and store it in variable sum Sum = num1 + num2 + num3;
// Print the sum Printf("\nSum of the 3 numbers is: %d", sum);
Return 0; } |
Output:
Enter the 1st number: 2
Enter the 2nd number: 3
Enter the 3rd number: 5
Sum of the 3 numbers is: 10
One problem, many solutions: The solution to an algorithm can be or cannot be more than one. It means that while implementing the algorithm, there can be more than one method to do implement it. For example, in the above problem to add 3 numbers, the sum can be calculated with many ways like:
- + operator
- Bit-wise operators
- . . Etc
How to Analyse an Algorithm?
For a standard algorithm to be good, it must be efficient. Hence the efficiency of an algorithm must be checked and maintained. It can be in two stages:
4. Priori Analysis: “Priori” means “before”. Hence Priori analysis means checking the algorithm before its implementation. In this, the algorithm is checked when it is written in the form of theoretical steps. This Efficiency of an algorithm is measured by assuming that all other factors, for example, processor speed, are constant and have no effect on the implementation. This is done usually by the algorithm designer. It is in this method, that the Algorithm Complexity is determined.
5. Posterior Analysis: “Posterior” means “after”. Hence Posterior analysis means checking the algorithm after its implementation. In this, the algorithm is checked by implementing it in any programming language and executing it. This analysis helps to get the actual and real analysis report about correctness, space required, time consumed etc.
What is Algorithm Complexity and How to find it?
An algorithm is defined as complex based on the amount of Space and Time it consumes. Hence the Complexity of an algorithm refers to the measure of the Time that it will need to execute and get the expected output, and the Space it will need to store all the data (input, temporary data and output). Hence these two factors define the efficiency of an algorithm.
The two factors of Algorithm Complexity are:
- Time Factor: Time is measured by counting the number of key operations such as comparisons in the sorting algorithm.
- Space Factor: Space is measured by counting the maximum memory space required by the algorithm.
Therefore the complexity of an algorithm can be divided into two types:
8. Space Complexity: Space complexity of an algorithm refers to the amount of memory that this algorithm requires to execute and get the result. This can be for inputs, temporary operations, or outputs.
How to calculate Space Complexity?
The space complexity of an algorithm is calculated by determining following 2 components:
- Fixed Part: This refers to the space that is definitely required by the algorithm. For example, input variables, output variables, program size, etc.
- Variable Part: This refers to the space that can be different based on the implementation of the algorithm. For example, temporary variables, dynamic memory allocation, recursion stack space, etc.
Therefore, Space complexity  of any algorithm P is
of any algorithm P is  , where C is the fixed part and S(I) is the variable part of the algorithm, which depends on instance characteristic I.
, where C is the fixed part and S(I) is the variable part of the algorithm, which depends on instance characteristic I.
Example: Consider the below algorithm for Linear Search
Step 1: START
Step 2: Get the array in arr and the number to be searched in x
Step 3: Start from the leftmost element of arr[] and one by one compare x with each element of arr[]
Step 4: If x matches with an element, Print True.
Step 5: If x doesn’t match with any of elements, Print False.
Step 6: END
Here, There are 2 variables arr, and x, where the arr is variable part and x is fixed part. Hence S(P) = 1+1. Now, space depends on data types of given variables and constant types and it will be multiplied accordingly.
9. Time Complexity: Time complexity of an algorithm refers to the amount of time that this algorithm requires to execute and get the result. This can be for normal operations, conditional if-else statements, loop statements, etc.
How to calculate Time Complexity?
The time complexity of an algorithm is also calculated by determining following 2 components:
- Constant time part: Any instruction that is executed just once comes in this part. For example, input, output, if-else, switch, etc.
- Variable Time Part: Any instruction that is executed more than once, say n times, comes in this part. For example, loops, recursion, etc.
Therefore, Time complexity  of any algorithm P is
of any algorithm P is  , where C is the constant time part and TP(I) is the variable part of the algorithm, which depends on instance characteristic I.
, where C is the constant time part and TP(I) is the variable part of the algorithm, which depends on instance characteristic I.
Example: In the algorithm of Linear Search above, the time complexity is calculated as follows:
Step 1: --Constant Time
Step 2: --Constant Time
Step 3: --Variable Time (Till the length of the Array, say n, or the index of the found element)
Step 4: --Constant Time
Step 5: --Constant Time
Step 6: --Constant Time
Hence, T(P) = 5 + n, which can be said as T(n).
Steps to solve logical and numerical problems
1. Read the problem at least three times (or however many makes you feel comfortable)
You can’t solve a problem you don’t understand. There is a difference between the problem and the problem you think you are solving. It’s easy to start reading the first few lines in a problem and assume the rest of it because it’s similar to something you’ve seen in the past. If you are making even a popular game like Hangman, be sure to read through any rules even if you’ve played it before. I once was asked to make a game like Hangman that I realized was “Evil Hangman” only after I read through the instructions (it was a trick!).
Sometimes I’ll even try explaining the problem to a friend and see if her understanding of my explanation matches the problem I am tasked with. You don’t want to find out halfway through that you misunderstood the problem. Taking extra time in the beginning is worth it. The better you understand the problem, the easier it will be to solve it.
Let’s pretend we are creating a simple function selectEvenNumbers that will take in an array of numbers and return an array evenNumbers of only even numbers. If there are no even numbers, return the empty array evenNumbers.
Function selectEvenNumbers() {
// your code here
}
Here are some questions that run through my mind:
- How can a computer tell what is an even number? Divide that number by 2 and see if its remainder is 0.
- What am I passing into this function? An array
- What will that array contain? One or more numbers
- What are the data types of the elements in the array? Numbers
- What is the goal of this function? What am I returning at the end of this function? The goal is to take all the even numbers and return them in an array. If there are no even numbers, return an empty array.
2. Work through the problem manually with at least three sets of sample data
Take out a piece of paper and work through the problem manually. Think of at least three sets of sample data you can use. Consider corner and edge cases as well.
Corner case: a problem or situation that occurs outside of normal operating parameters, specifically when multiple environmental variables or conditions are simultaneously at extreme levels, even though each parameter is within the specified range for that parameter.
Edge case: problem or situation that occurs only at an extreme (maximum or minimum) operating parameter
For example, below are some sets of sample data to use:
[1]
[1, 2]
[1, 2, 3, 4, 5, 6]
[-200.25]
[-800.1, 2000, 3.1, -1000.25, 42, 600]
When you are first starting out, it is easy to gloss over the steps. Because your brain may already be familiar with even numbers, you may just look at a sample set of data and pull out numbers like2, 4, 6 and so forth in the array without fully being aware of each and every step your brain is taking to solve it. If this is challenging, try using large sets of data as it will override your brain’s ability to naturally solve the problem just by looking at it. That helps you work through the real algorithm.
Let’s go through the first array [1]
- Look at the only element in the array [1]
- Decide if it is even. It is not
- Notice that there are no more elements in this array
- Determine there are no even numbers in this provided array
- Return an empty array
Let’s go through the array [1, 2]
- Look at the first element in array [1, 2]
- It is 1
- Decide if it is even. It is not
- Look at the next element in the array
- It is 2
- Decide if it is even. It is even
- Make an array evenNumbers and add 2 to this array
- Notice that there are no more elements in this array
- Return the array evenNumbers which is [2]
I go through this a few more times. Notice how the steps I wrote down for [1] varies slightly from [1, 2]. That is why I try to go through a couple of different sets. I have some sets with just one element, some with floats instead of just integers, some with multiple digits in an element, and some with negatives just to be safe.
3. Simplify and optimize your steps
Look for patterns and see if there’s anything you can generalize. See if you can reduce any steps or if you are repeating any steps.
- Create a function selectEvenNumbers
- Create a new empty array evenNumbers where I store even numbers, if any
- Go through each element in the array [1, 2]
- Find the first element
- Decide if it is even by seeing if it is divisible by 2. If it is even, I add that to evenNumbers
- Find the next element
- Repeat step #4
- Repeat step #5 and #4 until there are no more elements in this array
- Return the array evenNumbers, regardless of whether it has anything in it
This approach may remind you of Mathematical Induction in that you:
- Show it is true for n = 1, n = 2, ...
- Suppose it is true for n = k
- Prove it is true for n = k + 1
4. Write pseudocode
Even after you’ve worked out general steps, writing out pseudocode that you can translate into code will help with defining the structure of your code and make coding a lot easier. Write pseudocode line by line. You can do this either on paper or as comments in your code editor. If you’re starting out and find blank screens to be daunting or distracting, I recommend doing it on paper.
Pseudocode generally does not actually have specific rules in particular but sometimes, I might end up including some syntax from a language just because I am familiar enough with an aspect of the programming language. Don’t get caught up with the syntax. Focus on the logic and steps.
For our problem, there are many different ways to do this. For example, you can use filter but for the sake of keeping this example as easy to follow along as possible, we will use a basic for loop for now (but we will use filter later when we refactor our code).
Here is an example of pseudocode that has more words:
Function selectEvenNumberscreate an array evenNumbers and set that equal to an empty array for each element in that array
see if that element is even
if element is even (if there is a remainder when divided by 2)
add to that to the array evenNumbersreturn evenNumbers
Here is an example of pseudocode that has fewer words:
Function selectEvenNumbersevenNumbers = []for i = 0 to i = length of even Numbers
if (element % 2 === 0)
add to that to the array evenNumbersreturn evenNumbers
Either way is fine as long as you are writing it out line-by-line and understand the logic on each line.
Refer back to the problem to make sure you are on track.
5. Translate pseudocode into code and debug
When you have your pseudocode ready, translate each line into real code in the language you are working on. We will use JavaScript for this example.
If you wrote it out on paper, type this up as comments in your code editor. Then replace each line in your pseudocode.
Then I call the function and give it some sample sets of data we used earlier. I use them to see if my code returns the results I want. You can also write tests to check if the actual output is equal to the expected output.
SelectEvenNumbers([1])
selectEvenNumbers([1, 2])
selectEvenNumbers([1, 2, 3, 4, 5, 6])
selectEvenNumbers([-200.25])
selectEvenNumbers([-800.1, 2000, 3.1, -1000.25, 42, 600])
I generally use console.log() after each variable or line or so. This helps me check if the values and code are behaving as expected before I move on. By doing this, I catch any issues before I get too far. Below is an example of what values I would check when I am first starting out. I do this throughout my code as I type it out.
Function selectEvenNumbers(arrayofNumbers) {let evenNumbers = []
console.log(evenNumbers) // I remove this after checking output
console.log(arrayofNumbers) // I remove this after checking output}
After working though each line of my pseudocode, below is what we end up with. // is what the line was in pseudocode. Text that is bolded is the actual code in JavaScript.
// function selectEvenNumbers
function selectEvenNumbers(arrayofNumbers) {// evenNumbers = []
let evenNumbers = []// for i = 0 to i = length of evenNumbers
for (var i = 0; i < arrayofNumbers.length; i++) {// if (element % 2 === 0)
if (arrayofNumbers[i] % 2 === 0) {// add to that to the array evenNumbers
evenNumbers.push(arrayofNumbers[i])
}
}// return evenNumbers
return evenNumbers
}
I get rid of the pseudocode to avoid confusion.
Function selectEvenNumbers(arrayofNumbers) {
let evenNumbers = []for (var i = 0; i < arrayofNumbers.length; i++) {
if (arrayofNumbers[i] % 2 === 0) {
evenNumbers.push(arrayofNumbers[i])
}
}return evenNumbers
}
Sometimes new developers will get hung up with the syntax that it becomes difficult to move forward. Remember that syntax will come more naturally over time and there is no shame in referencing material for the correct syntax later on when coding.
6. Simplify and optimize your code
You’ve probably noticed by now that simplifying and optimizing are recurring themes.
“Simplicity is prerequisite for reliability.”
— Edsger W. Dijkstra, Dutch computer scientist and early pioneer in many research areas of computing science
In this example, one way of optimizing it would be to filter out items from an array by returning a new array using filter. This way, we don’t have to define another variable evenNumbers because filter will return a new array with copies of elements that match the filter. This will not change the original array. We also don’t need to use a for loop with this approach. Filter will go through each item, return either true, to have that element in the array, or false to skip it.
Function selectEvenNumbers(arrayofNumbers) {
let evenNumbers = arrayofNumbers.filter(n => n % 2 === 0)
return evenNumbers
}
Simplifying and optimizing your code may require you to iterate a few times, identifying ways to further simplify and optimize code.
Here are some questions to keep in mind:
- What are your goals for simplifying and optimizing? The goals will depend on your team’s style or your personal preference. Are you trying to condense the code as much as possible? Is the goal to make it the code more readable? If that’s the case, you may prefer taking that extra line to define the variable or compute something rather than trying to define and compute all in one line.
- How else can you make the code more readable?
- Are there any more extra steps you can take out?
- Are there any variables or functions you ended up not even needing or using?
- Are you repeating some steps a lot? See if you can define in another function.
- Are there better ways to handle edge cases?
“Programs must be written for people to read, and only incidentally for machines to execute.”
— Gerald Jay Sussman and Hal Abelson, Authors of “Structure and Interpretation of Computer Programs”
7. Debug
This step really should be throughout the process. Debugging throughout will help you catch any syntax errors or gaps in logic sooner rather than later. Take advantage of your Integrated Development Environment (IDE) and debugger. When I encounter bugs, I trace the code line-by-line to see if there was anything that did not go as expected. Here are some techniques I use:
- Check the console to see what the error message says. Sometimes it’ll point out a line number I need to check. This gives me a rough idea of where to start, although the issue sometimes may not be at this line at all.
- Comment out chunks or lines of code and output what I have so far to quickly see if the code is behaving how I expected. I can always uncomment the code as needed.
- Use other sample data if there are scenarios I did not think of and see if the code will still work.
- Save different versions of my file if I am trying out a completely different approach. I don’t want to lose any of my work if I end up wanting to revert back to it!
“The most effective debugging tool is still careful thought, coupled with judiciously placed print statements.”
— Brian W. Kernighan, Computer Science Professor at Princeton University
8. Write useful comments
You may not always remember what every single line meant a month later. And someone else working on your code may not know either. That’s why it’s important to write useful comments to avoid problems and save time later on if you need to come back to it.
Stay away from comments such as:
// This is an array. Iterate through it.
// This is a variable
I try to write brief, high-level comments that help me understand what’s going on if it is not obvious. This comes in handy when I am working on more complex problems. It helps understand what a particular function is doing and why. Through the use of clear variable names, function names, and comments, you (and others) should be able to understand:
- What is this code for?
- What is it doing?
9. Get feedback through code reviews
Get feedback from your teammates, professors, and other developers. Check out Stack Overflow. See how others tackled the problem and learn from them. There are sometimes several ways to approach a problem. Find out what they are and you’ll get better and quicker at coming up with them yourself.
“No matter how slow you are writing clean code, you will always be slower if you make a mess.”
— Uncle Bob Martin, Software Engineer and Co-author of the Agile Manifesto
10. Practice, practice, practice
Even experienced developers are always practicing and learning. If you get helpful feedback, implement it. Redo a problem or do similar problems. Keep pushing yourself. With each problem you solve, the better a developer you become. Celebrate each success and be sure to remember how far you’ve come. Remember that programming, like with anything, comes easier and more naturally with time.
Flowchart
A flowchart is simply a graphical representation of steps. It shows steps in sequential order and is widely used in presenting the flow of algorithms, workflow or processes. Typically, a flowchart shows the steps as boxes of various kinds, and their order by connecting them with arrows.
What is a Flowchart?
A flowchart is a graphical representation of steps. It was originated from computer science as a tool for representing algorithms and programming logic but had extended to use in all other kinds of processes. Nowadays, flowcharts play an extremely important role in displaying information and assisting reasoning. They help us visualize complex processes, or make explicit the structure of problems and tasks. A flowchart can also be used to define a process or project to be implemented.
Flowchart Symbols
Different flowchart shapes have different conventional meanings. The meanings of some of the more common shapes are as follows:
Terminator
The terminator symbol represents the starting or ending point of the system.

Process
A box indicates some particular operation.

Document
This represents a printout, such as a document or a report.

Decision
A diamond represents a decision or branching point. Lines coming out from the diamond indicates different possible situations, leading to different sub-processes.

Data
It represents information entering or leaving the system. An input might be an order from a customer. Output can be a product to be delivered.

On-Page Reference
This symbol would contain a letter inside. It indicates that the flow continues on a matching symbol containing the same letter somewhere else on the same page.

Off-Page Reference
This symbol would contain a letter inside. It indicates that the flow continues on a matching symbol containing the same letter somewhere else on a different page.

Delay or Bottleneck
Identifies a delay or a bottleneck.

Flow
Lines represent the flow of the sequence and direction of a process.

When to Draw Flowchart?
Using a flowchart has a variety of benefits:
- It helps to clarify complex processes.
- It identifies steps that do not add value to the internal or external customer, including delays; needless storage and transportation; unnecessary work, duplication, and added expense; breakdowns in communication.
- It helps team members gain a shared understanding of the process and use this knowledge to collect data, identify problems, focus discussions, and identify resources.
- It serves as a basis for designing new processes.
Flowchart examples
Here are several flowchart examples. See how you can apply a flowchart practically.
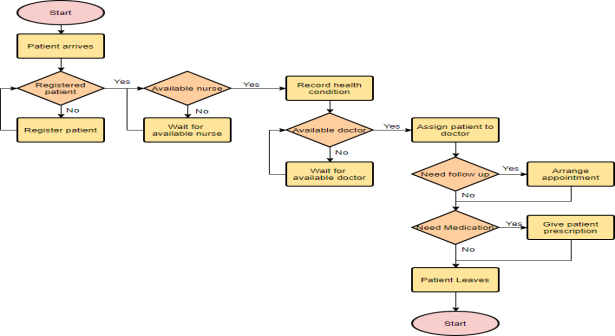
Flowchart Example – Medical Service
This is a hospital flowchart example that shows how clinical cases shall be processed. This flowchart uses decision shapes intensively in representing alternative flows.
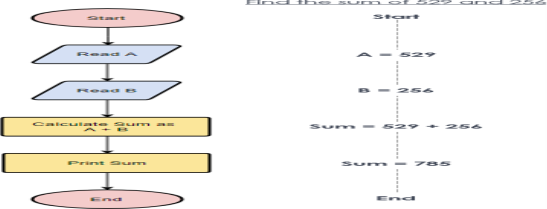
Flowchart Example – Simple Algorithms
A flowchart can also be used in visualizing algorithms, regardless of its complexity. Here is an example that shows how flowchart can be used in showing a simple summation process.
Flowchart Example – Calculate Profit and Loss
The flowchart example below shows how profit and loss can be calculated.
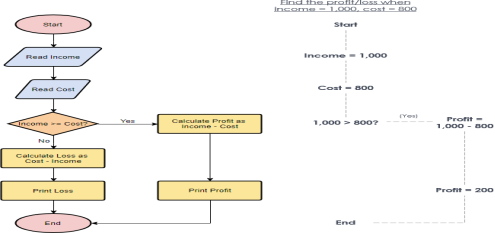
Creating a Flowchart in Visual Paradigm
Let’s see how to draw a flowchart in Visual Paradigm. We will use a very simple flowchart example here. You may expand the example when finished this tutorial.
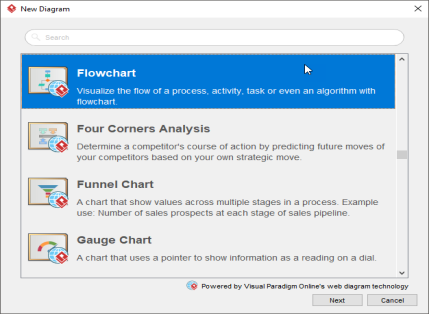
- Select Diagram > New from the main menu.
- In the New Diagram window, select Flowchart and click Next.
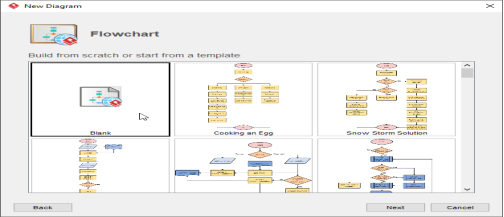
- You can start from an empty diagram or start from a flowchart template or flowchart example provided. Let’s start from a blank diagram. Select Blank and click Next.
- Enter the name of the flowchart and click OK.
- Let’s start by creating a Start symbol. Drag the Start shape from the diagram toolbar and drop it onto the diagram. Name it Start.
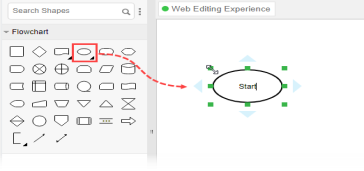
6. Create the next shape. Move your mouse pointer over the start shape. Press on the triangular handler on the right and drag it out.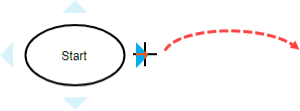
7. Release the mouse button. Select Flow Line > Process from the Resource Catalog.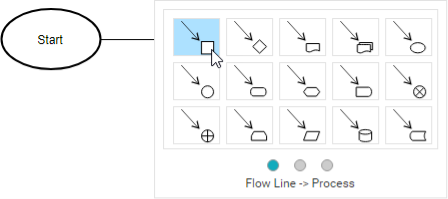
8. Enter Add items to Cart as the name of the process.
9. Follow the same steps to create two more processes Checkout Shopping Cart and Settle Payment.
10. End the flow by creating a terminator.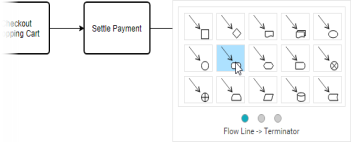
Your diagram should look like this:
11. Colour the shapes. Select Diagram > Format Panel from the main menu. Select a shape on the diagram and click update its colour through the Style setting in the Format Panel.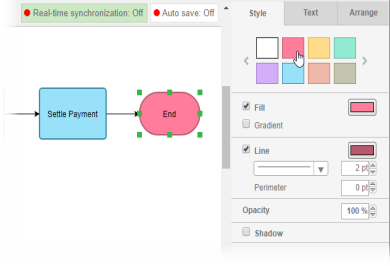
This is the final flowchart:
Pseudocode with examples
Pseudo code is a term which is often used in programming and algorithm based fields. It is a methodology that allows the programmer to represent the implementation of an algorithm. Simply, we can say that it’s the cooked up representation of an algorithm. Often at times, algorithms are represented with the help of pseudo codes as they can be interpreted by programmers no matter what their programming background or knowledge is. Pseudo code, as the name suggests, is a false code or a representation of code which can be understood by even a layman with some school level programming knowledge.
Algorithm: It’s an organized logical sequence of the actions or the approach towards a particular problem. A programmer implements an algorithm to solve a problem. Algorithms are expressed using natural verbal but somewhat technical annotations.
Pseudo code: It’s simply an implementation of an algorithm in the form of annotations and informative text written in plain English. It has no syntax like any of the programming language and thus can’t be compiled or interpreted by the computer.
Advantages of Pseudocode
- Improves the readability of any approach. It’s one of the best approaches to start implementation of an algorithm.
- Acts as a bridge between the program and the algorithm or flowchart. Also works as a rough documentation, so the program of one developer can be understood easily when a pseudo code is written out. In industries, the approach of documentation is essential. And that’s where a pseudo-code proves vital.
- The main goal of a pseudo code is to explain what exactly each line of a program should do, hence making the code construction phase easier for the programmer.
How to write a Pseudo-code?
- Arrange the sequence of tasks and write the pseudocode accordingly.
- Start with the statement of a pseudo code which establishes the main goal or the aim.
Example:
This program will allow the user to check
The number whether it's even or odd.
3. The way the if-else, for, while loops are indented in a program, indent the statements likewise, as it helps to comprehend the decision control and execution mechanism. They also improve the readability to a great extent.
4. Example:
5.
6. if "1"
7. print response
8. "I am case 1"
9.
10. if "2"
11. print response
12. "I am case 2"
13. Use appropriate naming conventions. The human tendency follows the approach to follow what we see. If a programmer goes through a pseudo code, his approach will be the same as per it, so the naming must be simple and distinct.
14. Use appropriate sentence casings, such as CamelCase for methods, upper case for constants and lower case for variables.
15. Elaborate everything which is going to happen in the actual code. Don’t make the pseudo code abstract.
16. Use standard programming structures such as ‘if-then’, ‘for’, ‘while’, ‘cases’ the way we use it in programming.
17. Check whether all the sections of a pseudo code is complete, finite and clear to understand and comprehend.
18. Don’t write the pseudo code in a complete programmatic manner. It is necessary to be simple to understand even for a layman or client, hence don’t incorporate too many technical terms.
Example:
Let’s have a look at this code
// This program calculates the Lowest Common multiple // for excessively long input values
Import java.util.*;
Public class LowestCommonMultiple {
Private static long LcmNaive(long numberOne, long numberTwo) {
Long lowestCommonMultiple;
LowestCommonMultiple = (numberOne * numberTwo) / greatestCommonDivisor(numberOne, NumberTwo);
Return lowestCommonMultiple; }
Private static long GreatestCommonDivisor(long numberOne, long numberTwo) {
If (numberTwo == 0) Return numberOne;
Return greatestCommonDivisor(numberTwo, NumberOne % numberTwo); } Public static void main(String args[]) {
Scanner scanner = new Scanner(System.in); System.out.println("Enter the inputs"); Long numberOne = scanner.nextInt(); Long numberTwo = scanner.nextInt();
System.out.println(lcmNaive(numberOne, numberTwo)); } } |
And here’s the Pseudo Code for the same.
This program calculates the Lowest Common multiple For excessively long input values
Function lcmNaive(Argument one, Argument two){
Calculate the lowest common variable of Argument 1 and Argument 2 by dividing their product by their Greatest common divisor product
Return lowest common multiple End } Function greatestCommonDivisor(Argument one, Argument two){ If Argument two is equal to zero Then return Argument one
Return the greatest common divisor
End }
{ In the main function
Print prompt "Input two numbers"
Take the first number from the user Take the second number from the user
Send the first number and second number To the lcmNaive function and print The result to the user } |
Examples
An algorithm is a procedure for solving a problem in terms of the actions to be executed and the order in which those actions are to be executed. An algorithm is merely the sequence of steps taken to solve a problem. The steps are normally "sequence," "selection, " "iteration," and a case-type statement.
In C, "sequence statements" are imperatives. The "selection" is the "if then else" statement, and the iteration is satisfied by a number of statements, such as the "while," " do," and the "for," while the case-type statement is satisfied by the "switch" statement.
Pseudocode is an artificial and informal language that helps programmers develop algorithms. Pseudocode is a "text-based" detail (algorithmic) design tool.
The rules of Pseudocode are reasonably straightforward. All statements showing "dependency" are to be indented. These include while, do, for, if, switch. Examples below will illustrate this notion.
Examples:
1.. If student's grade is greater than or equal to 60
Print "passed"
Else
Print "failed"
2. Set total to zero
Set grade counter to one
While grade counter is less than or equal to ten
Input the next grade
Add the grade into the total
Set the class average to the total divided by ten
Print the class average.
3.
Initialize total to zero
Initialize counter to zero
Input the first grade
While the user has not as yet entered the sentinel
Add this grade into the running total
Add one to the grade counter
Input the next grade (possibly the sentinel)
If the counter is not equal to zero
Set the average to the total divided by the counter
Print the average
Else
Print 'no grades were entered'
4.
Initialize passes to zero
Initialize failures to zero
Initialize student to one
While student counter is less than or equal to ten
Input the next exam result
If the student passed
Add one to passes
Else
Add one to failures
Add one to student counter
Print the number of passes
Print the number of failures
If eight or more students passed
Print "raise tuition"
Source code
If you’re neither a programmer nor a web designer, you probably don’t think much about what’s behind the programs and internet pages that you use every day. They are based in part on very complicated and long instructions to your computer. This command text is called source code. On the basis of a particular programming language, programmers lay out all of the rules for a computer-executable application. If the author writes an unnoticed error into their work that violates the specifications of the programming language, then the program either won’t function properly, will do nothing, or will crash.
What is source code?
Computers - regardless of whether it’s a home PC, modern smartphone, or scientific computer - work in the binary system: on/off, loaded/not loaded, 1/0. A sequence of bits instructs the computer as to what it should do. While commands were created in this way in the early days of computer technology, we have long since switched to writing applications in a human-readable programming language. This may sound strange at first since source code could also look like confused gibberish to a layman.
In context, “human-readable” is understood as the counterpart to the term “machine-readable”. While computers only work with number values, humans communicate with words. So, just like a foreign language, one must learn at least one of the various programming languages before being able to program, etc.
Different programming languages
There are hundreds of different programming languages. It’s impossible to say for certain which are better or worse, as it depends on the context of the project and the application for which the source code is used. Some of the most popular programming languages are:
- BASIC
- Java
- C
- C++
- Pascal
- Python
- PHP
- JavaScript
For the computer to understand these languages, however, they need to first be translated into machine code.
Compiler & Interpreter
For the computer to be able to further process the source code written by the programmer, there needs to be a translation between the two – this occurs in the form of an additional program. This assistance application can be in either the form of a compiler or an interpreter:
- Compiler: This application type translates (compiles) the source code into a code that the process understands and can execute. This machine code is saved in the form of an executable file.
- Interpreter: An interpreter translates the source code line for line and executes it directly. The translation process is much faster than a compiler but the execution is slower and requires a large amount of memory.
You don’t get to choose, either: each programming language determines whether a compiler or an interpreter is used in combination with it. Nowadays, an intermediate solution is being used increasingly often - Just-in-time compilation (JIT). This type of translation attempts to combine the advantages of both variants (quick analysis and quick execution) and is used in browsers, for example, to more effectively handle JavaScript, PHP, or Java.
Markup languages
The foundation of a website is also referred to as a source code. However, this is not a case of a programming language but rather the markup language HTML. A markup language determines how content is structured. For example, using HTML allows you to define headlines, paragraphs, or highlights. An HTML document isn’t a program in and of itself but may contain one, for example in the form of JavaScript Code. A similar principle applies for other markup languages, such as XML.
Reference
1. Byron Gottfried, Schaum's Outline of Programming with C, McGraw-Hill.
2. E. Balaguruswamy, Programming in ANSI C, Tata McGraw-Hill
3. Brian W. Kernighan and Dennis M. Ritchie, The C Programming Language, Prentice Hall
Of India




