Unit – 4
Learning Methods
● Learn probabilistic theories of the world from experience.
● We focus on the learning of Bayesian networks
● More specifically, input data (or evidence), learn probabilistic theories of the world (or hypotheses)
View learning as Bayesian updating of a probability distribution over the hypothesis space
H is the hypothesis variable, values h1, h2, . . ., prior P(H) jth observation dj gives the outcome of random variable Dj training data d = d1, . . . , dN
Given the data so far, each hypothesis has a posterior probability:
P(hi|d) = αP(d|hi) P(hi)
where P(d|hi) is called the likelihood
Predictions use a likelihood-weighted average over all hypotheses:
P(X|d) = Σi P (X|d, hi) P(hi|d) = Σi P(X|hi) P(hi|d)
Example
Suppose there are five kinds of bags of candies: 10% are h1: 100% cherry candies
20% are h2: 75% cherry candies + 25% lime candies 40% are h3: 50% cherry candies + 50% lime candies 20% are h4: 25% cherry candies + 75% lime candies 10% are h5: 100% lime candies
Then we observe candies drawn from some bag:
What kind of bag is it? What flavour will the next candy be?
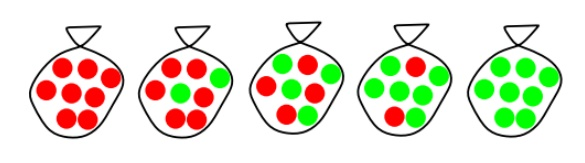
Fig 1: Example
1.The true hypothesis eventually dominates the Bayesian prediction given that the true hypothesis is in the prior
2.The Bayesian prediction is optimal, whether the data set be small or large[?] On the other hand
Learning with Complete Data
Statistical learning with complete data is the simplest task in the creation of statistical learning algorithms. A parameter learning problem is finding the numerical parameters for a probability model with a defined structure. We might be interested in learning the conditional probabilities in a Bayesian network with a specific structure, for example.
The data is complete when each data point contains values for each variable in the probability model being trained. When there is comprehensive data, the challenge of learning the parameters of a complex model is much simplified. We'll also look at the question of learning structure briefly.
Learning with Hidden Variables
Hidden variables (also known as latent variables) exist in many real-world situations and aren't visible in the data that can be learned. For example, medical records typically include the observed symptoms, the treatment administered, and possibly the treatment's outcome, but they rarely include a firsthand observation of the condition! One can wonder, “Why not develop a model without the illness if it isn't observed?” Figure shows the solution, which is a simple, fictitious heart disease diagnostic model. There are three predisposing variables as well as three symptoms to look out for (which are too depressing to name).
Assume that each variable can exist in three distinct states (e.g., none, moderate, and severe). When the hidden variable is eliminated, the network in (a) becomes the network in (b); the total number of parameters increases from 78 to 708. As a result, employing latent variables, the number of parameters required to construct a Bayesian network can be considerably decreased. As a result, the amount of data needed to learn the parameters can be decreased significantly.
Hidden variables are important, but they do complicate the learning problem. In Figure, for example, it is not obvious how to learn the conditional distribution for Heart Disease, given its parents, because we do not know the value of Heart Disease in each case; the same problem arises in learning the distributions for the symptoms.
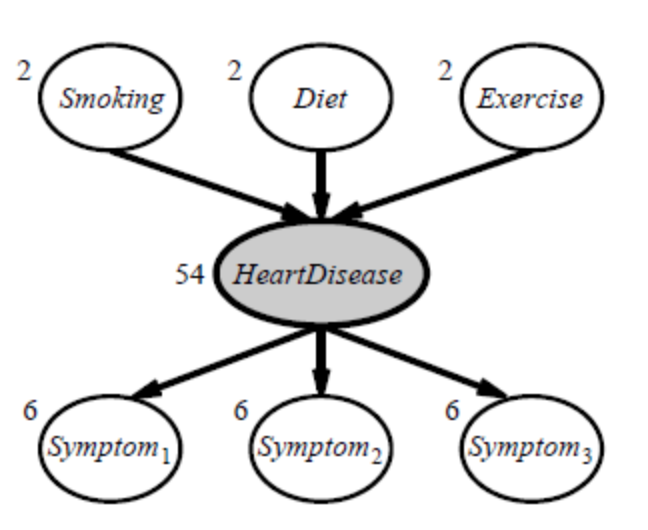
Fig 2: A simple diagnostic network for heart disease, which is assumed to be a hidden variable
Rote Learning
● Roughly speaking, rote learning is the most basic form of learning.
● Because the knowledge is simply transferred into the knowledge base without any alterations, it's also known as remembering. Rules and facts can be directly inputted.
● Knowledge that has been captured is referred to as a "knowledge base."
● In the conventional meaning, ontology development.
● Data caching is used to improve performance.
● Because computed values are preserved, this method can save a lot of time.
● If complex approaches are employed to use the recorded values faster and there is a generalization to reduce the volume of stored information to a tolerable level, the rote learning methodology can be used in intricate learning systems.
● This strategy is used by a checkers-playing algorithm to learn the board positions it analyzes in its look-ahead search.
● Complex learning systems are reliant on two key capabilities:
○ Organized storage of information: Data retrieval requires advanced techniques. It will take a lot less time than recomputing the data.
○ Generalization: The number of different objects that could potentially be stored is enormous. To keep the quantity of things in storage to a manageable amount.
Learning by taking advice
● This is the most basic and uncomplicated technique of instruction.
● A programmer builds a program that guides the computer to perform a task in this sort of learning. Once the system has been learned, it will be able to perform new tasks (i.e., programmed).
● Humans (experts), the internet, and other kinds of information are also available for guidance.
● In contrast to rote learning, this method of learning needs greater inference.
● As the stored knowledge in the knowledge base is transformed into an operational form, the reliability of the information source is always taken into account.
● The advice will be operationalized by the programs by converting it into a single or multiple expressions that comprise concepts and actions that the program can employ while running.
● Learning relies heavily on this ability to operationalize information. Explanation Based Learning incorporates this as well (EBL).
Key takeaway
When the program does not learn from advice, it can learn by generalizing from its own experiences.
● Learning by parameter adjustment
● Learning with macro-operators
● Learning by chunking
● The unity problem
Learning by parameter adjustment
● The learning system in this example uses an evaluation technique that combines data from various sources into a single static summary.
● For example, demand and production capacity might be combined into a single score to indicate the likelihood of increased output.
● However, defining how much weight each component should be given a priori is difficult.
● By guessing the correct settings and then letting the computer modify them based on its experience, the correct weight can be discovered.
● Features that appear to be strong indicators of overall performance will have their weights increased, while those that do not will have their weights reduced.
● This type of learning strategy is useful when there is a shortage of knowledge.
● In game programming, for example, factors such as piece advantage and mobility are combined into a single score to assess whether a particular board position is desired. This single score is nothing more than data that the algorithm has gathered through calculation.
● This is accomplished via programs' static evaluation functions, which combine several elements into a single score. This function's polynomial form is as follows:
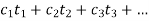
● The t words represent the values of the traits that contribute to the evaluation. The c terms are the coefficients or weights that are allocated to each of these values.
● When it comes to creating programs, deciding on the right value to give each weight might be tricky. As a result, the most important rule in parameter adjustment is to:
○ Begin by making an educated guess at the appropriate weight values.
○
○ Adjust the program's weight based on your previous experience.
○ Traits that appear to be good forecasters will have their weights increased, while features that look to be bad predictions will have their weights reduced.
● The following are significant factors that affect performance:
○ When should the value of a coefficient be increased and when should it be decreased?
■ The coefficients of good predictors should be increased, while the coefficients of undesirable predictors should be reduced.
■ The difficulty of properly assigning blame to each of the phases that led to a single outcome is referred to as the credit assignment system.
○ How much should the price change?
● Hill climbing is a type of learning technique.
● This strategy is particularly beneficial in situations when new knowledge is scarce or in programs where it is used in conjunction with more knowledge-intensive strategies.
Learning with Macro-Operators
● Macro-operators are collections of actions that can be handled together.
● The learning component saves the computed plan as a macro-operator once a problem is solved.
● The preconditions are the initial conditions of the just-solved problem, while the postconditions are the problem's outcomes.
● The problem solver makes good use of prior experience-based knowledge.
● By generalizing macro-operations, the issue solver can even tackle other challenges. To achieve generality, all constants in the macro-operators are substituted with variables.
● Despite the fact that the macro-operator’s multiple operators cause countless undesirable local changes, it can have a minimal global influence.
● Macro operators can help us develop domain-specific knowledge.
Learning by Chunking
● It's similar to chunking to learn with macro-operators. Problem-solving systems that use production systems are most likely to use it.
● A series of rules in the form of if-then statements makes up a production system. That is, what actions should be made in a specific situation. Bring an umbrella if it's raining, for example.
● Problem solvers employ rules to solve difficulties. Some of these rules may be more valuable than others, and the results are grouped together.
● Chunking can be used to gain a general understanding of search control.
● Chunks learned at the start of the problem-solving process can be employed at a later stage. The chunk is saved by the system to be used in future challenges.
The utility problem
● When knowledge is acquired in the hopes of improving a system's performance, it actually causes harm. In learning systems, this is referred to as the utility problem.
● The problem can be encountered in a wide range of AI systems, but it's particularly common in speedup learning. Speedup learning approaches are aimed to teach people control principles in order to assist them enhance their problem-solving skills. When these systems are given complete freedom to learn, they usually display the unwelcome attribute of actually slowing down.
● Although each control rule has a positive utility (improve performance), when combined, they have a negative utility (reduce performance) (degrade performance).
● The serial nature of modern hardware is one of the sources of the utility problem. The more control rules a system acquires, the longer it takes for the system to test them on each cycle.
● This type of utility analysis can be used to a wide range of learning challenges.
● Each control rule in the PRODIGY program has a utility measure. This metric considers the rule's average savings, the frequency with which it is used, and the cost of matching it.
● A proposed regulation is discarded or forgotten if it provides a negative utility.
Induction learning
Learning through Induction We have a collection of xi, f (xi) for 1in in supervised learning, and our goal is to determine 'f' using an adaptive approach. It's a machine learning method for inferring rules from facts or data. In logic, conditional or antecedent reasoning is the process of reasoning from the specific to the general. Theoretical studies in machine learning mostly concern supervised learning, a sort of inductive learning. An algorithm is provided with samples that are labeled in a useful way in supervised learning.
Inductive learning techniques, such as artificial neural networks, allow the real robot to learn simply from data that has already been collected. Another way is to let the bot learn everything in his environment by inducing facts from it. Inductive learning is the term for this type of learning. Finally, you may train the bot to evolve across numerous generations and improve its performance.
f(x) is the target function
An example is a pair [x, f(x)]
Some practical examples of induction are:
● Credit risk assessment.
○ The x is the property of the customer.
○ The f(x) is credit approved or not.
● Disease diagnosis.
○ The x are the properties of the patient.
○ The f(x) is the disease they suffer from.
● Face recognition.
○ The x are bitmaps of people’s faces.
○ The f(x) is to assign a name to the face.
● Automatic steering.
○ The x are bitmap images from a camera in front of the car.
○ The f(x) is the degree the steering wheel should be turned.
Two perspectives on inductive learning:
● Learning is the removal of uncertainty. Data removes some of the uncertainty. We are removing more uncertainty by selecting a class of hypotheses.
● Learning is guessing a good and small hypothesis class. It necessitates speculation. Because we don't know the answer, we'll have to rely on trial and error. You don't need to learn if you're confident in your domain knowledge. But we're not making educated guesses.
Key takeaway
You can learn with just one training session if you use explanation-based learning. Instead of memorizing several examples, the focus is on explanation-based learning to memorize a single, unique example. Take the Ludo game, for example. The buttons in a Ludo game are usually four distinct colors. For each color, there are four different squares.
Assume the primary colors are red, green, blue, and yellow. As a result, this game can only have four players at a time. Two members are chosen for one side (for example, green and red), while the remaining two are chosen for the opposing side (suppose blue and yellow). As a result, each opponent will play according to his own set of rules.
The four members share a small square box with symbols numbered one to six. One is the lowest number, and six is the highest, for which all processes have been completed. Any member of the first side will assault a member of the second, and vice versa. At any point throughout the game, players on one team can attack players on the opposing side.
Similarly, each button can be pressed and rejected individually, with one side eventually winning the game. At any time, the players on one side can attack the players on the other side. As a result, the performance of a single player might have an impact on the entire game.
Mitchell and colleagues defined explanation-based generalization (EBG) as an explanation-based learning strategy (1986). It is divided into two sections, the first of which explains the method and the second of which generalizes the method. In the first stage, the domain theory is used to eliminate all of the non-essential components of training examples in connection to the goal concept. The second phase is to widen the explanation as much as possible while remaining focused on the goal concept.
Discovery
Theory Driven Discovery - AM (1976)
AM is a program that teaches basic mathematics and set theory ideas.
AM has two inputs:
● a description of some set theory notions (in LISP form). Set union, intersection, and the empty set are examples.
● Instructions on how to solve math problems. Consider functions.
How does AM work?
AM employs many general-purpose AI techniques:
● A frame-based representation of mathematical concepts.
AM can create new concepts (slots) and fill in their values.
● Heuristic search employed
250 heuristics represent hints about activities that might lead to interesting discoveries.
How to employ functions, create new concepts, generalization etc.
● Hypothesis and test-based search.
● Agenda control of discovery process
AM discovered
● Integers – The elements of this set may be counted, and here is the image of this counting function — the integers — an intriguing set in and of itself.
● Addition – The counting function of the union of two disjoint sets
● Multiplication – Following the discovery of addition and multiplication as time-consuming set-theoretic operations, more effective hand-written descriptions were created.
● Prime number – Number factorization and numbers with only one factor have been identified.
● Golbach's Conjecture – The sum of two primes can be stated as an even number. For example, 28 = 17 + 11.
● Maximally Divisible Numbers – integers with as many variables as possible When a number k has more factors than any integer less than k, it is said to be maximally divisible. For example, the number 12 has six divisors: 1,2,3,4,6,12.
Data Driven Discovery -- BACON (1981)
Many discoveries are made from observing data obtained from the world and making sense of it -- E.g., Astrophysics - discovery of planets, Quantum mechanics - discovery of subatomic particles.
BACON is an attempt at providing such an AI system. BACON system outline:
● Starts with a set of variables for a problem.
○ E.g., BACON was able to derive the ideal gas law. It started with four variables p - gas pressure, V -- gas volume, n -- molar mass of gas, T -- gas temperature. Recall pV/nT = k where k is a constant.
● Values from experimental data from the problem are inputted.
● BACON holds some constant and attempts to notice trends in the data.
● Inferences made.
BACON has also been applied to Kepler's 3rd law, Ohm's law, conservation of momentum and Joule's law.
Clustering
● Clustering is the division of data into a large number of new groups.
● It's a common descriptive assignment in which the purpose is to characterize the data with a minimal number of categories or clusters. For example, we might want to group houses to discover distribution patterns.
● Clustering is a method of classifying a collection of physical or abstract objects into groups of similar ones.
● A cluster is a collection of data elements that are similar to one another but distinct from those in other clusters. Clustering analysis is a technique for organizing a large number of things into meaningful groupings.
● Clustering's goal is to maximize intra-class similarity while minimizing inter-class similarity.
○ Given N k-dimensional feature vectors, find a "meaningful" partition of the N examples into c subsets or groups
○ Discover the "labels" automatically
○ c may be given, or “discovered”
○ much more difficult than classification, since in the latter the groups are given, and we seek a compact description
AutoClass
● AutoClass is a Bayesian-based clustering system for discovering optimal classes in large datasets.
● The purpose of Bayesian classification is to find the best class description that predicts the data in a model space given a collection X=X1,..., Xn of data instances Xi with unknown classes.
● The likelihood of belonging to a particular class is expressed.
● An instance is not assigned to a single class; instead, it has a chance to belong to any of the classes that are available (represented as weight values).
● AutoClass calculates the likelihood of each instance belonging to each class C, and then assigns a set of weights wij= (Ci / SjCj) to each instance.
● Weighted statistics relevant to each term of the class likelihood are created to estimate the class model.
● The most computationally costly stage is categorization. It calculates the weights of each instance for each class, as well as the classification parameters.
Analogy
Learning by analogy entails gaining new knowledge about an input entity by transferring it from a similar entity that is already known.
Fig 3: Analogies
Analogies can be used to derive hydraulic laws such as Kirchoff's and Ohm's laws.
Central intuition supporting learning by analogy:
When two entities are similar in some ways, they are likely to be similar in other ways as well.
Examples of analogies:
Pressure Drop is like Voltage Drop
A variable in a programming language is like a box.
Transformational analogy
Find a similar solution and adapt it to the current situation, substituting as necessary.
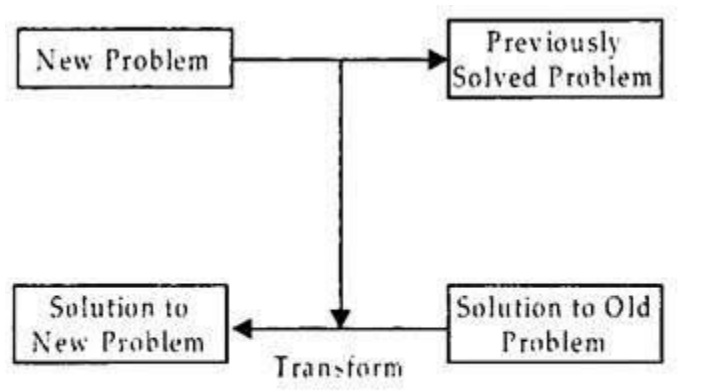
Fig 4: Transformational analogy
Example: Geometry
If you know about line segment lengths and have proof that particular lines are equal, you can make comparable claims about angles.
We know that lines RO = NY and angles AOB = COD
We have seen that RO + ON = ON + NY - additive rule.
So, we can say that angles AOB + BOC = BOC + COD
So, by a transitive rule line RN = OY So similarly angle AOC = BOD
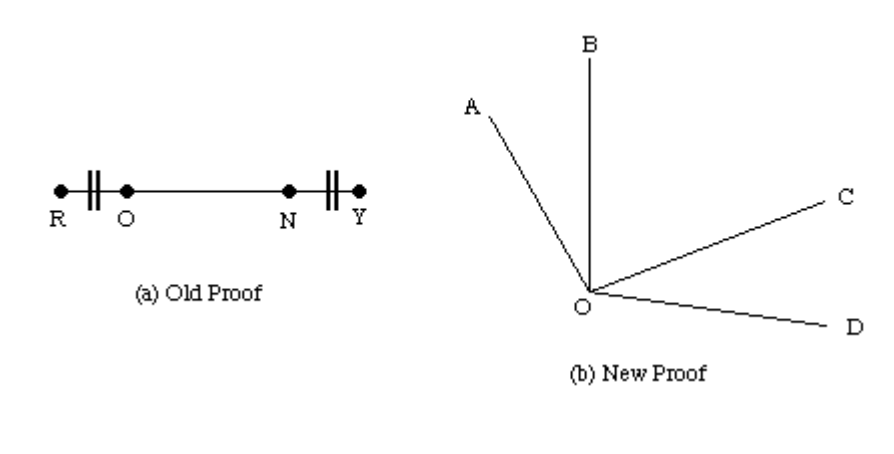
Fig 5: Example
Derivational analogy
According to a certain similarity metric, if two problems match within a certain threshold, they share substantial elements.
The answer to the retrieved problem is changed incrementally until it matches the new problem's requirements.
In a transformative comparison, the final response is the only thing that matters. It makes no difference how the issue was resolved. The steps involved in the history of the problem solution are frequently relevant.
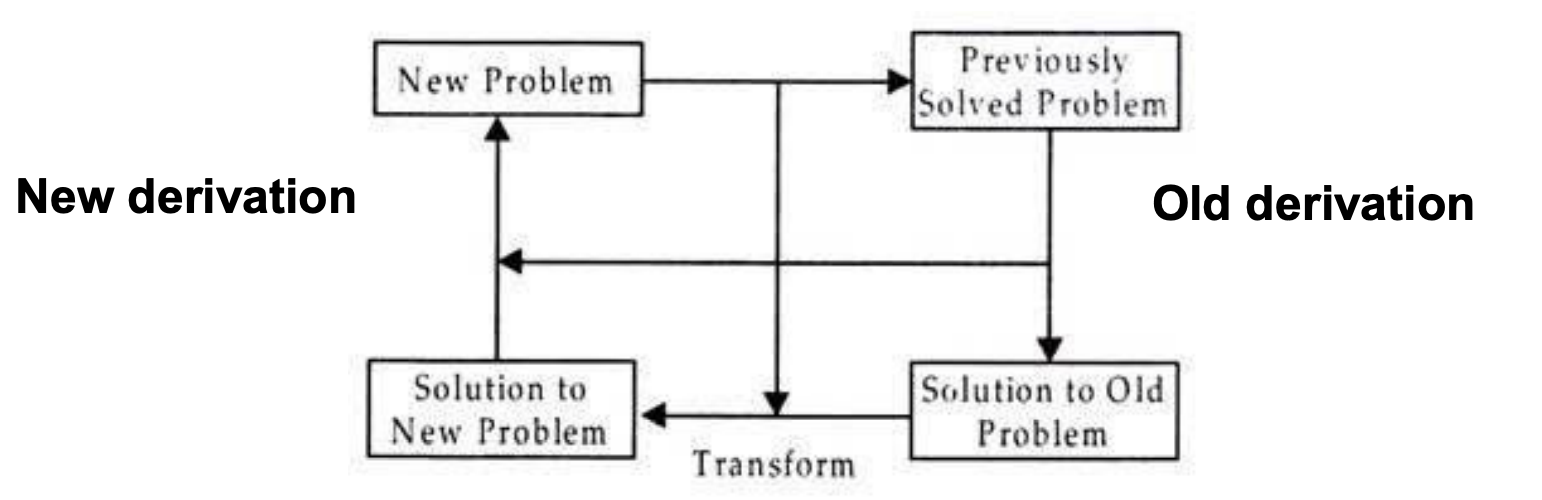
Fig 6: Derivational analogy
Formal learning theory
● Valiant's Theory of the Learnable categorizes situations according to how difficult they are to learn.
● Formally, a device can learn a concept if it can generate an algorithm that will correctly classify future cases with probability 1/h given positive and negative examples.
● Complexity of learning a function is decided by three factors:
○ The error tolerance (h)
○ The number of binary features present in the example (t)
○ Size of rules necessary to make the discrimination (f)
● The system is considered to be trainable if the number of training examples is a polynomial in h, t, and f.
● Learning feature descriptions is an example.
● The usage of knowledge will be quantified using mathematical theory.
Gray? | Mammal? | Large? | Vegetarian? | Wild? |
|
|
+ + + - + + | + + + + - + | + - + + + + | + - + + - + | + + + + + - | + + - - - + | Elephant Elephant Mouse Giraffe Dinosaur Elephant |
Key takeaway
A neural network is made up of neurons, which are interconnected processing components that work together to provide an output function. In order for a neural network's output to work, the individual neurons inside the network must cooperate. Well-designed neural networks are trainable systems that can often "learn" to solve complicated issues from a set of examples and then extend that "learned knowledge" to solve new problems, making them self-adaptive.
A network of biological neurons is referred to as a neural network. A neural network is made up of nodes or units, which are highly interconnected entities. Each unit receives a weighted set of inputs and produces a result.
A neural network is first and foremost a graph, with patterns represented as numerical values attached to the graph's nodes and patterns transformed using simple message-passing techniques. A number of units are shown in the graph, with weighted unidirectional links between them.
In most cases, one unit's output becomes an input for another. Units with external inputs and outputs may also be present. The graph's nodes are classified as input or output nodes, and the graph as a whole can be considered as a representation of a multivariate function that connects inputs and outputs. The input/output function is parameterized and can be changed using a learning method by attaching numerical values (weights) to the graphs' linkages.
In a larger sense, a neural network architecture can be thought of as a statistical processor that makes specific probabilistic assumptions about data. Figure illustrates one example of a possible neural network structure.
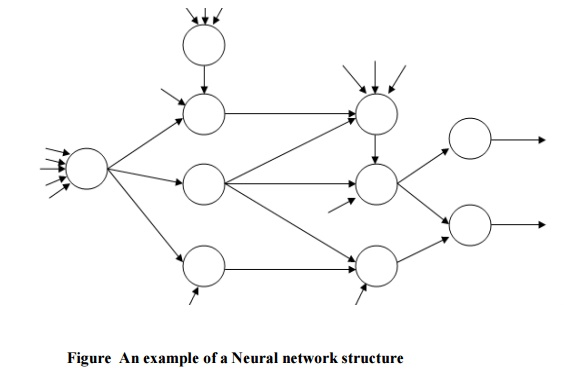
Fig 7: Example of neural net
Genetic learning
Genetic algorithms function by producing a set of random solutions and forcing them to compete in an environment where only the best survives. They are based on the notion of natural selection. Each of the solutions in the set represents a chromosome. Learning algorithms based on genetic algorithms are based on natural adaptation and evolution models. Through processes that simulate population genetics and survival of the fittest, these learning methods increase their performance.
A population is subjected to an environment that sets pressures on its members in the realm of genetics. Matting and replication are reserved for those who adapt successfully. Reproduction, crossover, and mutation are the three basic genetic operators used in most genetic algorithms. To evolve a new population, these are blended. The algorithm employs these operators and the fitness function to steer its search for the best answer, starting with a random selection of solutions.
The fitness function makes an educated guess as to how good the answer is and provides a measure of its capacity. The genetic operators copy systems based on human evolution principles. The main advantage of the genetic algorithm formulation is that fairly accurate results may be obtained using a very simple algorithm.
The evolutionary algorithm is a mechanism for determining a good solution to a problem based on feedback from previous attempts at solving it. The GA's attempts to solve a problem are judged by the fitness function. GA is unable to deduce the answer to a problem, but they can learn from the fitness function.
The GA follows the following steps: Generate, Evaluate, Value Assignment, Mate, and Mutate. Allowing the GA to run for a specified amount of cycles is one of the criteria. Allowing the GA to run until a reasonable solution is discovered is the second option.
Mutation is also an operation that ensures that all locations in the rule space can be reached, and that every conceivable rule in the rule space may be evaluated. To avoid random wandering in the search space, the mutation operator is normally used only sparingly.
Let's look at the genetic algorithm in more detail:
Step 1: Generate the initial population.
Step 2: Calculate the fitness function of each individual.
Step 3: Some sort of performance utility values or the fitness values are assigned to individuals.
Step 4: New populations are generated from the best individuals by the process of selection.
Step 5: Perform the crossover and mutation operation.
Step 6: Replace the old population with the new individuals.
Step 7: Perform step-2 until the goal is reached.
Key takeaway
Expert systems are computer programs that are designed to tackle complicated issues in a certain domain at a level of human intellect and expertise.
An expert system is a piece of software that can deal with difficult problems and make choices in the same way as a human expert can. It achieves it by using reasoning and inference techniques to retrieve knowledge from its knowledge base based on the user's requests.
The performance of an expert system is based on the knowledge stored in its knowledge base by the expert. The better the system functions, the more knowledge is saved in the KB. When typing in the Google search box, one of the most common examples of an ES is a suggestion of spelling problems.
An expert system is a computer simulation of a human expert. It can alternatively be described as a computer software that imitates the judgment and conduct of a human or an organization with substantial knowledge and experience in a certain field.
In such a system, a knowledge base containing accumulated experience and a set of rules for applying the knowledge base to each specific case presented to the program are usually provided. Expert systems also leverage human knowledge to solve problems that would normally necessitate human intelligence. These expert systems use computers to transmit expertise knowledge as data or rules.
Knowledge Base
● It includes domain-specific, high-quality information.
● To be intelligent, you must have knowledge. The acquisition of extremely accurate and precise knowledge is critical to the success of any ES.
● A knowledge base is a sort of storage that maintains information gathered from various specialists in a specific topic. It is regarded as a large repository of knowledge. The Expert System will be more precise as the knowledge base grows.
● It's similar to a database that stores data and rules for a specific domain or subject.
● The knowledge base can alternatively be viewed as a collection of items and their qualities. A lion, for example, is an item with the properties of being a mammal, not being a domestic animal, and so on.
Components of Knowledge Base
● Factual Knowledge: The knowledge which is based on facts and accepted by knowledge engineers comes under factual knowledge.
● Heuristic Knowledge: This knowledge is based on practice, the ability to guess, evaluation, and experiences.
Knowledge Representation:
It is used to formalize the knowledge stored in the knowledge base using the If-else rules.
Expert system shell
A professional system Shell is a development environment for software. It includes the fundamental elements of expert systems. By configuring and instantiating these components, a shell is coupled with a prescribed way for developing applications.
Information collection, knowledge Base, reasoning, explanation, and user interface are the generic components of a shell. The knowledge base and reasoning engine are the most important components.
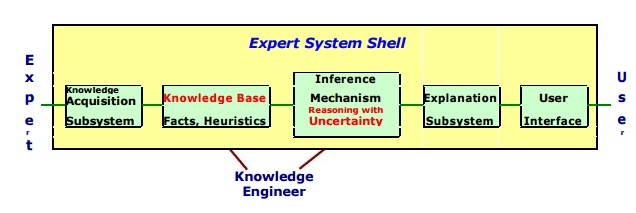
Fig 8: Expert system shell
● Knowledge Base – A database that contains both factual and heuristic data. The expert system tool provides one or more knowledge representation schemes for representing knowledge about the application area. Some tools make use of frames (objects) and IF-THEN logic. PROLOG uses logical assertions to express knowledge.
● Reasoning Engine – Inference methods for manipulating symbolic information and knowledge in the knowledge base establish a path of reasoning in addressing a problem. From simple modus ponens backward chaining of IF-THEN rules to Case-Based reasoning, the inference process can be anything.
● Knowledge Acquisition subsystem – A subsystem to help experts in build knowledge bases. However, collecting knowledge, needed to solve problems and build the knowledge base, is the biggest bottleneck in building expert systems.
● Explanation subsystem – A subsystem that describes the actions of the system. The explanation could be anything from how the final or intermediate answers were reached to justifying the need for further data.
● User Interface – A way for the user to communicate with you. In most cases, the user interface is not part of the expert system technology. It has previously received little notice. However, the user interface of an Expert system can make a significant difference in user satisfaction.
Key takeaway
Knowledge acquisition is the process of gathering or collecting information from a variety of sources. It refers to the process of adding new information to a knowledge base while simultaneously refining or upgrading current information. Acquisition is the process of increasing a system's capabilities or improving its performance at a certain activity.
As a result, it is the creation and refinement of knowledge toward a certain goal. Acquired knowledge contains facts, rules, concepts, procedures, heuristics, formulas, correlations, statistics, and any other important information. Experts in the field, text books, technical papers, database reports, periodicals, and the environment are all possible sources of this knowledge.
Knowledge acquisition is a continuous process that takes place throughout a person's life. Knowledge acquisition is exemplified via machine learning. It could be a method of self-study or refining aided by computer programs. The newly acquired knowledge should be meaningfully linked to previously acquired knowledge.
The data should be accurate, non-redundant, consistent, and thorough. Knowledge acquisition helps with tasks like knowledge entry and knowledge base upkeep. The knowledge acquisition process builds dynamic data structures in order to refine current information.
The knowledge engineer's role is equally important in the development of knowledge refinements. Knowledge engineers are professionals who elicit knowledge from specialists. They write and edit code, operate several interactive tools, and create a knowledge base, among other things, to combine knowledge from multiple sources.
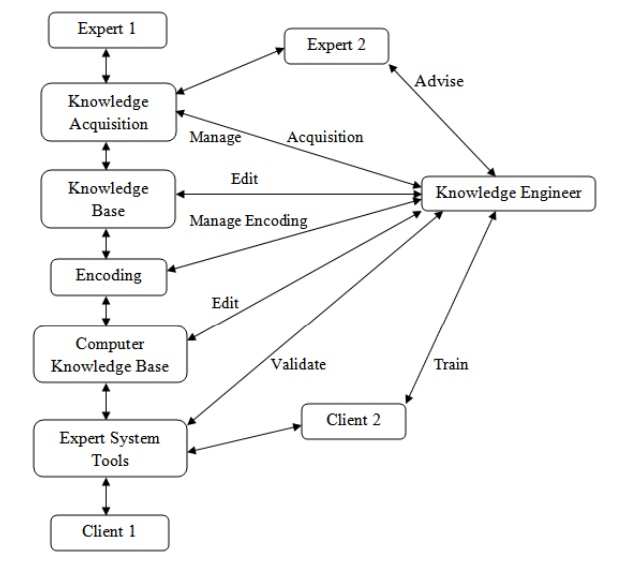
Fig 9: Knowledge Engineer’s Roles in Interactive Knowledge Acquisition
Key takeaway
References:




