Unit - 1
Introduction to Programming
Disk : Generally, a disk is a round plate on which data can be encoded. There are two basic types of disks: magnetic disks and optical disks.
Magnetic Disks
In magnetic disks, the data is encoded as microscopic magnetized needles on the disk's surface. You can record and erase data on a magnetic disk any number of times Magnetic disks come in a number of different forms:
● Floppy disk: A typical 5¼-inch floppy disk can hold 360K or 1.2MB megabytes. 3½-inch floppies normally store 720K, 1.2MB or 1.44MB of data. Floppy disks or obsolete today.
● Harddisk :Hard disks can store anywhere from 20MB to more than 1-TB (terabyte). Hard disks are also from 10 to 100 times faster than floppy disks.
● Removable Cartridge : Removable cartridges are hard disks encased in a metal or plastic cartridge, so you can remove them just like a floppy disk. Removable cartridges are fast, though usually not as fast as fixed hard disks.
Memory : The memory stores all input data, instructions, and intermediate data from the processes. Primary memory and secondary memory are the two forms of memory. Primary memory is located inside the CPU, while secondary memory is located outside of it.
Memory is primarily of three types −
● Cache Memory
● Primary Memory/Main Memory
● Secondary Memory
Cache Memory
Cache memory is a high -speed semiconductor memory which can speed up the CPU. It acts as a buffer between the CPU and the main memory. It is used to hold those parts of data and programs which are most frequently used by the CPU. The parts of data and programs are transferred from the disk to cache memory by the operating system, from where the CPU can access them.
Advantages
The advantages of cache memory are as follows −
● Cache memory is faster than main memory.
● It consumes less access time as compared to main memory.
● It stores the program that can be executed within a short period of time.
● It stores data for temporary use.
Disadvantages
The disadvantages of cache memory are as follows −
● Cache memory has limited capacity.
● It is too expensive.
Primary Memory (Main Memory)
Primary memory holds only those data and instructions on which the computer is currently working. It has a limited capacity and data is lost when power is switched off. It is generally made up of semiconductor devices. These memories are not as fast as registers. The data and instruction required to be processed resides in the main memory. It is divided into two subcategories RAM and ROM.
Characteristics of Main Memory
● These are semiconductor memories.
● It is known as the main memory.
● Usually volatile memory.
● Data is lost in case power is switched off.
● It is the working memory of the computer.
● Faster than secondary memories.
● A computer cannot run without the primary memory.
Secondary Memory
This type of memory is also known as external memory or non-volatile. It is slower than the main memory. These are used for storing data/information permanently. CPU directly does not access these memories, instead they are accessed via input-output routines. The contents of secondary memories are first transferred to the main memory, and then the CPU can access it. For example, disk, CD-ROM, DVD, etc.
Characteristics of Secondary Memory
● These are magnetic and optical memories.
● It is known as the backup memory.
● It is a non-volatile memory.
● Data is permanently stored even if power is switched off.
● It is used for storage of data in a computer.
● Computer may run without the secondary memory.
● Slower than primary memories.
Operating system : The operating system is the program that is responsible for the proper operation of all hardware components and their interoperability in order to complete tasks successfully (OS).
Processor : The logic circuitry that reacts to and processes the basic instructions that drive a machine is known as a processor. A processor's four primary functions are retrieve, decode, execute, and write back.
A processor's fundamental components are:
● The arithmetic logic unit (ALU) performs arithmetic and logic operations on instructions' operands.
● The floating point unit (FPU), also known as a math or numeric coprocessor, is a specialized coprocessor that can manipulate numbers faster than the basic microprocessor circuitry.
● Register : Instructions and other data are stored in registers. The ALU receives operands from registers, which store the results of operations.
Program stored and executed operating system
Whenever you save your program(anything) into a file (any kind of file, say ‘add.c’), it automatically gets stored in the secondary storage that is the hard disk. The Operating System’s kernel (kernel’s File management system) does it for you.
When you run a program, it is loaded into the main/primary memory of the computer called RAM (the entire program is transferred to the RAM, by a small program called the loader (which often comes with the compiler i.e. is a part of the compiler).
The program instructions are executed in the ALU (Arithmetic-Logic Unit) of the CPU (in its registers like the Accumulator). In order to execute the instructions , the CPU fetches the values of the variables (say, int a =10; int b =20;) in the program from the RAM, and stores the results also in the RAM (int sum =30;), which is then sent to the output buffer stream (stdout) , which prints the results (30) on the computer console/terminal, the Windows kernel (kernel’s I/O management system) does the printing .
Compilers : Compiler, computer program that converts source code written in a high-level language into a collection of machine-language instructions that a digital computer's CPU can understand. Compilers are vast programs that have error-checking and other features.
Compiler is a program that translates source code into object code. The compiler derives its name from the way it works, looking at the entire piece of source code and collecting and reorganizing the instructions. Thus, a compiler differs from an interpreter, which analyses and executes each line of source code in succession, without looking at the entire program. The advantage of interpreters is that they can execute a program immediately. Compilers require some time before an executable program emerges. However, programs produced by compilers run much faster than the same programs executed by an interpreter.
Some compilers convert high-level languages to intermediate assembly languages, which are then translated (assembled) into machine code by an assembler. Other compilers explicitly produce machine language.
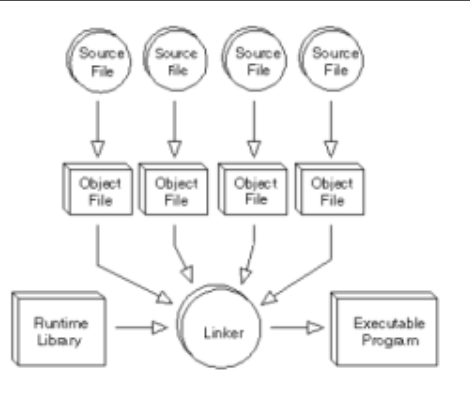
Fig 1: compilers
Key takeaway :
An algorithm is the finite set of English statements which are designed to accomplish the specific task. Study of any algorithm is based on the following four criteria
1.Design of algorithm : This is the first step in the creation of an algorithm. Design of algorithm includes the problem statement which tells the user about the area for which the algorithm is required. After the problem statement, the next important thing required is the information about available and required resources. The last thing required in the design of the algorithm phase is information about the expected output.
2.Validation of algorithm : Once an algorithm is designed , it is necessary to validate it for several possible inputs and make sure that algorithm is providing correct output for every input. This process is known as algorithm validation. The purpose of the validation is to assure us that this algorithm will work correctly independently of the issues concerning the programming language it will eventually be written in.
3.Analysis of algorithm : Analysis of algorithms is also called as performance analysis. This phase refers to the task of determining how much computing time and storage an algorithm requires. The efficiency is measured in best case, worst case and average case analysis.
4.Testing of algorithm : This phase is about testing of a program which is coded as per the algorithm. Testing of such program consists of two phases:
● Debugging: It is the process of executing programs on sample data sets to determine whether faulty results occur or not and if occur, to correct them.
● Profiling : Profiling or performance measurement is the process of executing a correct program on data sets and measuring the time and space it takes to compute the result
Characteristics of an algorithm
● Input: Algorithms must accept zero or more inputs.
● Output: Algorithms must provide at least one quantity.
● Definiteness: Algorithms must consist of clear and unambiguous instructions.
● Finiteness: Algorithms must contain a finite set of instructions and algorithms will terminate after a finite number of steps.
● Effectiveness: Every instruction in the algorithm must be very basic and effective.
Uses of algorithm
● Algorithms provide an independent layout of the program.
● It is easy to develop the program in any desired language with help of layout.
● Algorithm representation is very easy to understand.
● To design algorithms there is no need for expertise in programming languages.
Key takeaway :
There are three ways to represent an algorithm. Consider the following algorithm of addition of two numbers
Step 1 : Start
Step 2 : Read a number, say x and y
Step 3 : Add x and y
Step 4 : Display Addition
Step 5 : Stop
1.Flowcharts : A flow chart is a diagrammatic / pictorial representation of an algorithm. It is the simplest way of representing an algorithm. Initially an algorithm is represented in the form of flowchart and then flowchart is given to the programmer to express it in some programming language. Logical error detection is very easy in flowchart as it shows the flow of operations in diagrammatic form. Once the flowchart is ready it is very easy to write a program in terms of statements of a programming language. Following are the symbols used in designing the flowcharts.
2.Pseudo code : Pseudo code is the combination of English statements with programming methodology. In pseudo code, there is no restriction of following the syntax of the programming language. Pseudo codes cannot be compiled. It is just a previous step of developing a code for a given algorithm.
3.Program: In this way of representation, complete algorithm is represented using some programming language by following the complete syntax of programming language.

Fig 2: notation of flow chart
Pseudo Code Syntax
● INPUT – denotes that a user will be entering data.
● OUTPUT – denotes that a screen output will be shown.
● WHILE – this is a loop (iteration that has a condition at the beginning)
● FOR – a loop that counts (iteration)
● REPEAT – UNTIL – a loop (iteration) that has a condition at the end
● IF – THEN – ELSE – a decision (selection) in which a choice is made
● Any instructions that arise during a selection or iteration are typically indented.
Example : Average of three numbers
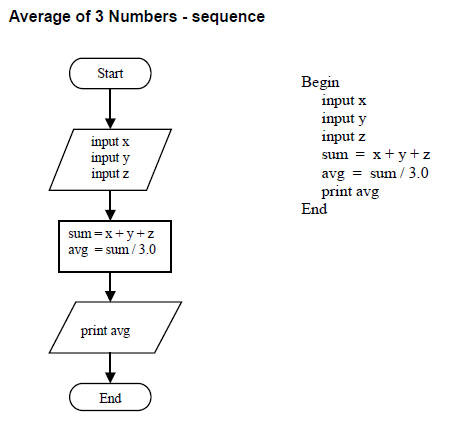
Fig 3: flowchart and pseudocode
Source code :
Source code is the list of human-readable instructions that a programmer writes—often in a word processing program—when he is developing a program. The source code is run through to turn it in the compiler to machine code called object code.
Key takeaway :
Variables are the names you give to computer memory locations which are used to store values in a computer program.
Here are the following three simple steps −
● Create variables with appropriate names.
● Store your values in those two variables.
● Retrieve and use the stored values from the variables.
When creating a variable, we need to declare the data type it contains.
Programming languages define data types differently.
For example, almost all languages differentiate between ‘integers’ (or whole numbers, eg 12), ‘non-integers’ (numbers with decimals, eg 0.24), and ‘characters’ (letters of the alphabet or words).
● char – a single 16-bit Unicode character, such as a letter, decimal or punctuation symbol.
● boolean – can have only two possible values: true (1) or false (0). This data type is useful in conditional statements.
● byte - has a minimum value of -128 and a maximum value of 127 (inclusive).
● short– has a minimum value of -32,768 and a maximum value of 32,767
● int: – has a minimum value of -2,147,483,648 and a maximum value of 2,147,483,647 (inclusive).
● long – has a minimum value of -9,223,372,036,854,775,808 and a maximum value of 9,223,372,036,854,775,807 (inclusive).
● float – a floating point number with 32-bits of precision
● double – this is a double precision floating point number.
Key takeaway :
A syntax error is an error in the source code of a program. Since computer programs must follow strict syntax to compile correctly, any aspects of the code that do not conform to the syntax of the programming language will produce a syntax error.
• Spelling mistakes
• Missing out quotes
• Missing out brackets
• Using uppercase characters in keywords e.g. IF instead of if
• Missing out a colon or semicolon at end of a statement
• Using tokens in the wrong order
A logic error (or logical error) is a ‘bug’ or mistake in a program’s source code that results in incorrect or unexpected behaviour. It is a type of runtime error that may simply produce the wrong output or may cause a program to crash while running.
Key takeaway :
Source code is the C program that you write in your editor and save with a ‘ .C ‘ extension which is un-compiled when written for the first time or whenever a change is made in it and saved.
Object code is the output of a compiler after it processes the source code. The object code is usually a machine code, also called a machine language, which can be understood directly by a specific type of CPU. However, some compilers are designed to convert source code into an assembly language or some other programming language. An assembly language is a human-readable notation using the mnemonics in the ISA of that particular CPU.
Executable (also called the Binary) is the output of a linker after it processes the object code. A machine code file can be immediately executable, runnable as a program , or it might require linking with other object code files for example libraries to produce a complete executable program.
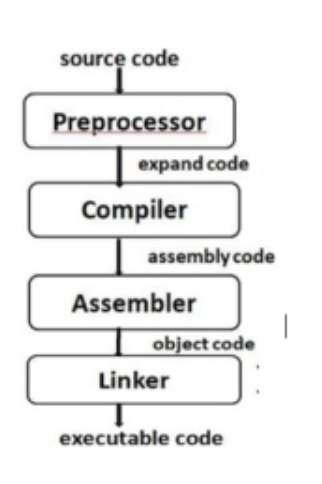
Fig 4: object and executable code
Key takeaway :
References:




